前言
先谈谈我偏偏选了这个2017年的老文章进行复现的动机吧(●’◡’●).很简单其实就是封面这张 苗族少女服饰吸引了我,我也是因此用Google去搜索这张图片(可能被下蛊了哈哈),最后发现这张图片最早出于这篇论文,于是抱着 这份喜欢就读了这篇文章 ,顶图附上一张 贵州西江千户苗寨的图片,希望将来有机会到此一游,欣赏一下苗族服饰~
超分辨率(Super Resolution)是一种从低分辨率LR图像中估计出高分辨率HR图像的技术。SRGAN 是GAN网络用于图像超分辨率的开篇之作,本篇内容主要基于论文Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network , 代码实现主要参考了https://github.com/eriklindernoren/PyTorch-GAN
SRGAN提出的背景
这篇论文发表于2017年,在此之前的SR算法的优化目标通常是最小化生成的高分辨率图像与真实高分辨率图之间的均方误差MSE。这样做很方便,因为最小化MSE同时也最大化了峰值信噪比PSNR,这是评估和比较SR算法的常用指标。然而MSE和PSNR捕捉感知相关差异(如高纹理细节)的能力非常有限,因为它们是基于像素级(pixel-wise)图像差异定义的。

观察上面图片就容易知道这一点,其中最高的PSNR并不一定反映出感知上更好的SR结果。(图片中括号指标代表PNSR/SSIM)
总结:早期的研究主要采用MSE作为优化目标,这是一种像素级的误差函数,优化MSE虽然能够提高相似度指标,但是超分出的图像很容易缺失像图像细节纹理 这样的高频信号,因此看着会更模糊一些(比如上图SRResNet虽然由最高的PNSR 23.53dB和SSIM 0.7832,但是纹理细节不如SRGAN).
SRGAN的核心贡献
SRGAN引入一种基于感知相似性而非像素空间相似性的损失函数 。
感知损失该如何理解?
不妨先谈谈CNN,随着卷积神经网络CNN的广泛应用,我们不得疑问?为什么CNN能像人类一样认识别出比如图像的内容、位置等等。我的理解是卷积神经网络能够对输入进行特征提取(Feature Extract),这些中间层提取的特征是一些抽象高维的特征比如图像的纹理、色彩、形状等等。而我们人类同样对图像的感知更关注整体结构和语义信息(如边缘、纹理、物体形状),而非逐个像素的绝对差异。可见CNN中间的特征抽取 类似 于我们人类的感知过程。
感知损失该如何计算呢?
上面谈到CNN就是在做一个特征抽取的过程,因此很自然我们计算感知损失正是先通过一个卷积神经网络的中间层对 超分的图像和原高分辨率图像进行一个特征提取,提取到的这部分特征就像我们人类的“感知”信息,接着计算两张图“感知”信息的差异就行了。
像素级的MSE损失计算公式:
lMSESR=r2WH1x=1∑rWy=1∑rH(Ix,yHR−GθG(ILR)x,y)2
可见pixel-wise的MSE是对图像的每个像素点进行损失计算。
感知损失:
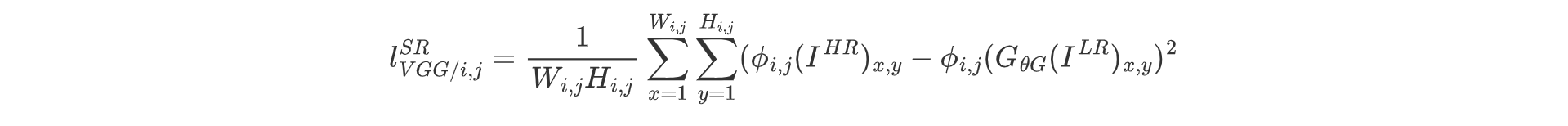
上式中i,j表示在VGG19网络中第i个最大池化层之前(激活后)由第j个卷积获得的特征图. 可见感知损失则是通过VGG的中间层提取特征后的特征图在进行逐像素点的误差计算。
VGG特征提取模块代码示例:
这里使用了预训练的vgg19 去了其特征层中的前18层
1
2
3
4
5
6
7
8
9
10
11
12
| from torchvision.models import vgg19
class FeatureExtractor(nn.Module):
def __init__(self):
super().__init__()
vgg_model = vgg19(weights=torchvision.models.VGG19_Weights.IMAGENET1K_V1)
self.feature_extractor = nn.Sequential(
*list(vgg_model.features.children())[:18]
)
def forward(self,imgs):
return self.feature_extractor(imgs)
|
网络架构
SRGAN本质也是一个GAN网络,包含生成器和判别器两部分,下面附上原文采用的网络架构:

解释:上图中的字母数字组合比如“k9n64s1”代表kernel_size=9,num of feature maps特征图为64(即输出通道),stride(步长)为1.
残差块代码示例:
生成器网络中采用了B个残差块堆叠(原文中B=16),使用ParametricReLU激活函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
| class ResidualBlock(nn.Module):
def __init__(self, in_features):
super().__init__()
self.res_block = nn.Sequential(
nn.Conv2d(in_channels=in_features,out_channels=in_features,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=in_features,momentum=0.8),
nn.PReLU(),
nn.Conv2d(in_channels=in_features,out_channels=in_features,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=in_features,momentum=0.8),
)
def forward(self,x):
return x+self.res_block(x)
|
生成器代码示例:
按照图中结构搭建生成器,其中B=16,PixelShuffle模块将(N,C∗r2,H,W)−−>(N,C,rH,rW) 实现上采样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class GeneratorResnet(nn.Module):
def __init__(self,in_channels=3,out_channels=3,num_residual_block=16):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=64,kernel_size=9,stride=1,padding=9//2),
nn.PReLU()
)
res_blocks = []
for i in range(num_residual_block):
res_blocks.append(ResidualBlock(64))
self.res_block = nn.Sequential(*list(res_blocks))
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=64,momentum=0.8)
)
self.upsampling = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=256),
nn.PixelShuffle(upscale_factor=2),
nn.PReLU(),
nn.Conv2d(in_channels=64,out_channels=256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(num_features=256),
nn.PixelShuffle(upscale_factor=2),
nn.PReLU()
)
self.conv3 = nn.Conv2d(in_channels=64,out_channels=out_channels,kernel_size=9,stride=1,padding=9//2)
def forward(self,x):
out1 = self.conv1(x)
out_res = self.res_block(out1)
out2 = self.conv2(out_res)
out = out1+out2
out = self.upsampling(out)
out = self.conv3(out)
return out
|
判别器代码示例:
原论文中使用LeakyReLU激活(α=0.2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, stride=1, padding=1))
if not first_block:
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
|
损失函数
值得提醒的是论文中生成器的感知损失包含两部分,内容损失和对抗损失之和。而后续论文中大部分都只把“内容损失”称作“感知损失”。
lSR=losscontent+10−3lossadversarial
而对抗损失函数则是GAN网络常用的优化目标:
lossadversarial=n=1∑N−logDθD(GθG(ILR))
损失函数定义代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
| criterion_GAN = torch.nn.MSELoss()
criterion_content = torch.nn.MSELoss()
loss_GAN = criterion_GAN(discriminator(gen_hr), valid)
gen_features = feature_extractor(gen_hr)
real_features = feature_extractor(imgs_hr)
loss_content = criterion_content(gen_features, real_features.detach())
loss_G = loss_content + 1e-3 * loss_GAN
|
实验
数据我采用了VOC2012数据集,数据集链接:https://pan.quark.cn/s/16e631a655a8
数据集处理代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import glob
import random
import os
import numpy as np
import torch
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.5, 0.5, 0.5])
class ImageDataset(Dataset):
def __init__(self, root, hr_shape):
hr_height, hr_width = hr_shape
self.lr_transform = transforms.Compose(
[
transforms.Resize((hr_height // 4, hr_width // 4), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]
)
self.hr_transform = transforms.Compose(
[
transforms.Resize((hr_height, hr_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]
)
self.files = sorted(glob.glob(root + "/*.*"))
def __getitem__(self, index):
img = Image.open(self.files[index % len(self.files)])
img_lr = self.lr_transform(img)
img_hr = self.hr_transform(img)
return {"lr": img_lr, "hr": img_hr}
def __len__(self):
return len(self.files)
|
由于没有低分辨率LR图像,因此将数据集中每张图像通过BICUBIC 双三次插值缩放得到低分辨率图像。
实验细节
这里的超参数参考了开源代码实现方法,值得一提的是Adma优化器的betas 设定分别为0.5,0.999,学习率为0.0002。
1
2
| opt_g = torch.optim.Adam(generator.parameters(),lr=lr,betas=(0.5,0.999))
opt_d = torch.optim.Adam(discriminator.parameters(),lr=lr,betas=(0.5,0.999))
|
实验结果
训练了大概25个epoch,我写了一个inference脚本对原图进行采样,得到的低分辨率,超分图如下:

代码后面我会全部上传到我的Github仓库https://github.com/sukiAme7/SRGAN ,敬请关注~
总结
SRGAN是GAN网络在超分辨率任务上的开山之作。即使SRGAN中部分设计虽然已经过时(2017年嘛),但它的整体训练架构被一直沿用了下来. SRGAN这篇论文主要关注点如下:
同时也能看出GAN 网络本质是去学习一个分布。因此GAN会记忆一些和数据集相关的信息。在输入信息不足的超分辨率、图像补全等任务中,GAN记忆的数据集信息有很有用了。
