
机器学习(1):认识机器学习
什么是机器学习?
从字面意思上来说,机器学习就是让机器去学习 .而传统的学习算法过程则是让机器去执行 ,让机器去完成一个具体的任务而不是学习怎么去做。机器学习一个比较早的应用就是 垃圾邮件分辨 ,试想一下比较传统的计算机解决问题思路,可能是编写规则去定义什么是“垃圾邮件”,让计算机去执行这个定义,那么输入一封垃圾邮件的信息扔进这样一个传统算法就能得到一个输出(是否是垃圾邮件)。
但是显然这种传统的解决思路存在一个很大的问题—规则是很难定义的 ,到底什么样的邮件是一个垃圾邮件?我们是很难制定出一个精准的规则的来判断它们。同时一个更致命的问题就是–规则是在不断变化的 ,就算我们制定出了一个规则,但规则本身也是在不断变化的,随着时间推移垃圾邮件可能以前是"恭喜中奖!点击领取100万美元",而现在变成了"您上周购买的联想Yoga笔记本延长保修确认",变得越来越难以分辨。
现实世界的大部分问题都具备这种特性,即它的规则是很难定义的,同时规则也在不断变化。比如图像识别领域的一个基本问题就是分辨出这张图像是什么,更简单一些比如下面这张图片是猫还是狗?我们人类很容易分辨出来左边是狗,右边是猫,但是如果更细致的去问究竟是什么让你认为左侧是狗右侧是猫?或者你会说右侧猫有这种 猫科动物特有的斑纹,但是也能找到很多猫没有这种斑纹,同时还能找到一些狗拥有这些斑纹,更不用我们人类所说的 “斑纹”这种特征用计算机量化描述的话 究竟什么样是有斑纹?显然规则是很难编写的 ,也正因如此 图像识别领域 大量使用 机器学习的方法(深度学习)。

人类怎么学习?
传统的经典算法执行的那些任务是让计算机执行容易,让人类执行困难。比如给一百万个数据进行排序,让我们人类执行效率会非常低,但是让计算机执行很快就能完成。可是机器学习处理的事情正好相反, 可以发现像垃圾邮件检测、图像识别、人脸识别、数字识别等等这些任务对于我们人类来说很容易,但对于机器来说很困难。这不得让我们思考人类到底是如何进行学习的?
我们人类的学习过程是一个典型的经验学习的过程。举一个例子比如上面的猫狗图片,我们是如何看一眼就能分辨出来呢?首先我们需要有一定的样本资料,比如我们小时候在电视里、生活中会见到各种各样的猫和狗,然后经过我们大脑的学习归纳整理总结,最终形成了我们的知识和经验。因此以后我们遇到类似的猫狗,我们马上能根据这些知识经验做出反应(即判断出来这是一只猫还是一只狗)。
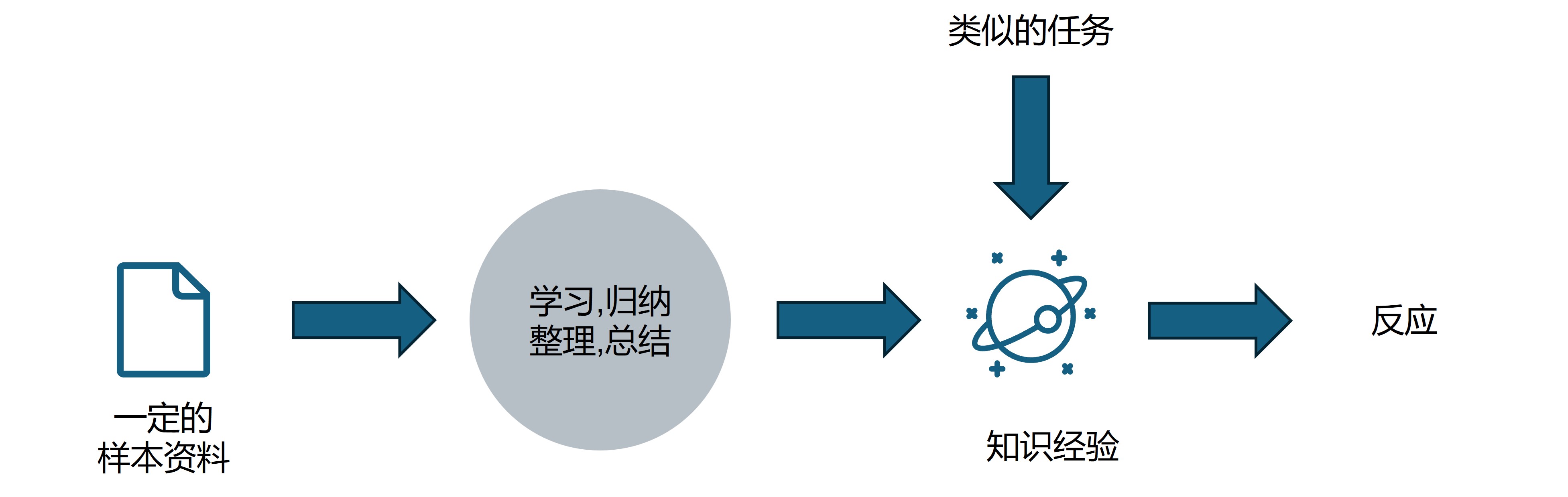
而机器学习的过程跟我们人类的学习过程是十分相似的(下图和上图)。最大的区别可能在于我们人类的大脑是非常厉害的,我们只需要非常少的资料就可以归纳总结出适用性非常强的知识或者经验,我们可能只需要几张猫狗图片就能分辨出猫狗的区别,也许我们可能很难阐述出这种区别是什么,但是面对一张新的照片我们都能以比较高的正确率分辨出是猫还是狗。但是机器是比较笨的,它的优势主要在于运算效率非常高,所以可以处理海量资料。
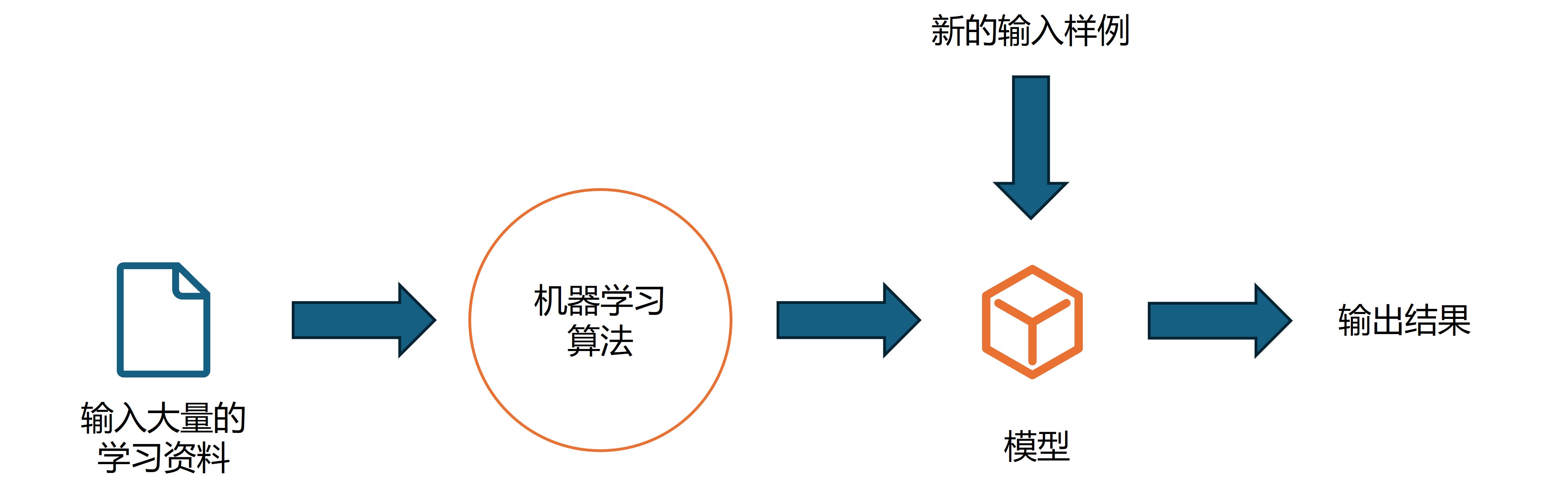
机器学习基础概念
数据
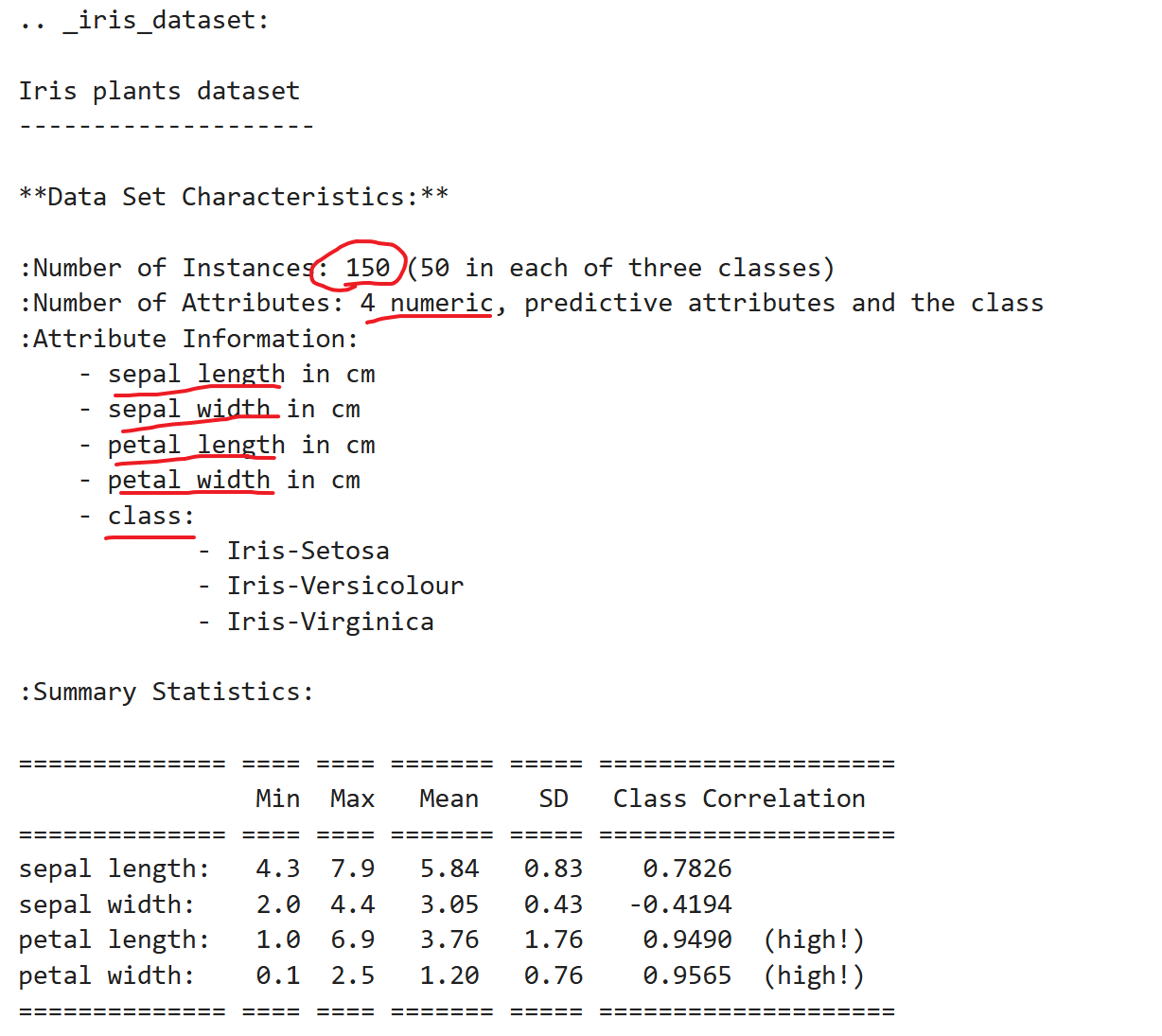
以著名的鸢尾花数据为例来谈谈机器学习中的数据 。
1 | pip install scikit-learn # 安装scikit-learn库 |
1 | from sklearn.datasets import load_iris |
可以发现数据总共有150条,包含四个特征萼片长度、宽度和花瓣长度、宽度,分为3类Setosa、Versicolour、Virginica.
从中随便取出3条数据,每条数据 都包含四个特征以及其对应的种类标签。
| 萼片长度 | 萼片宽度 | 花瓣长度 | 花瓣宽度 | 种类 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Se(0) |
| 7.0 | 3.2 | 4.7 | 1.4 | Ve(1) |
| 6.3 | 3.3 | 6 | 2.5 | Vi(2) |
为了计算机处理方便,种类不是用字符串表示,而是被数字化为0,1,2来表示种类。
-
数据整体叫数据集(data set)
-
每一行数据称为一个样本(sample)
-
除了最后一列,每一列都表达了样本的一个特征(feature)
-
最后一列,称为标记(label)
第i个样本行写作 第i个样本第j个特征值写做 ,同时把一般特征向量 表示为列向量

为了方便绘制,取萼片的长度、宽度两个特征分别作为 横轴、数轴在一个平面绘制散点图
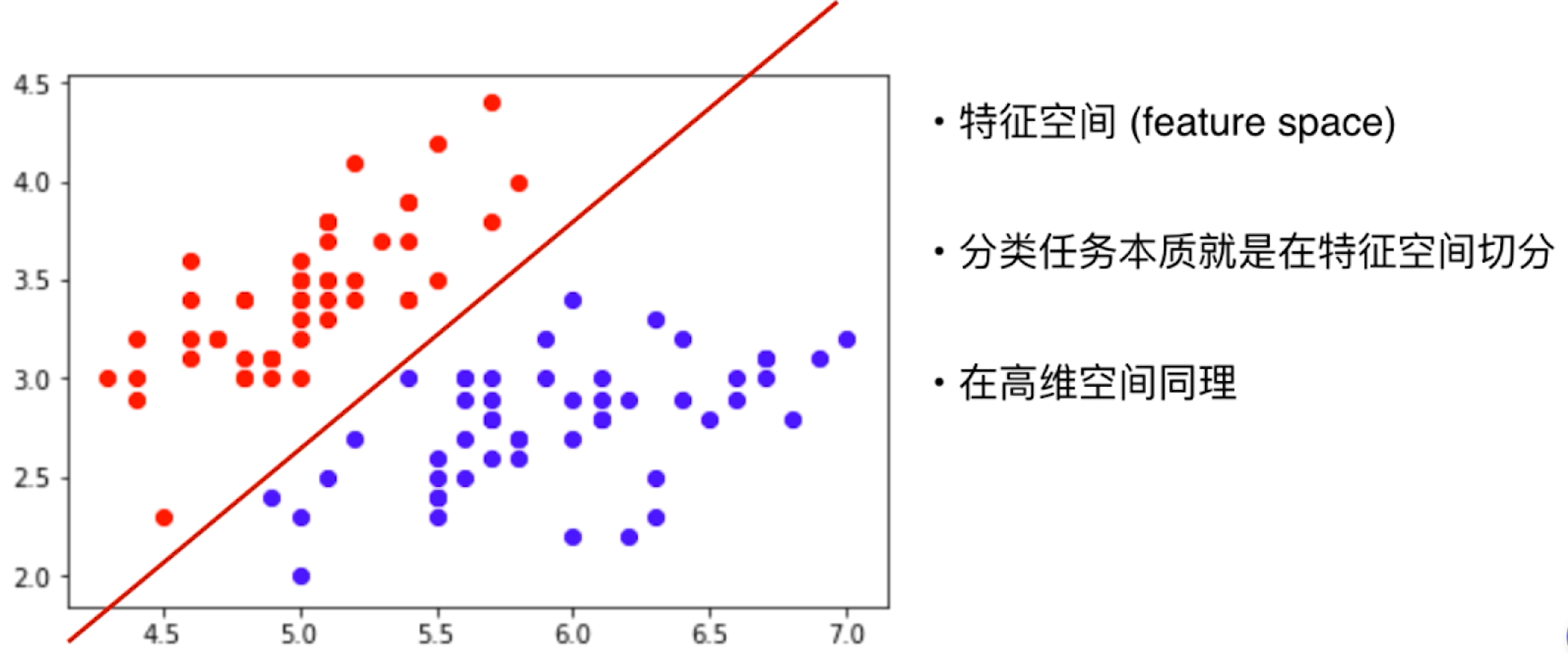
这里的特征萼片长度 宽度都是有语义的,即我们知道 每个特征每个数字代表什么意思,但是在机器学习中大多时候特征也是很抽象的 ,即特征也可以是没有语义的、抽象的、朴素的甚至与最终完成任务毫无关系,比如 图像识别中的像素点

机器学习的基本任务
上面我们谈了数据,接下来我们谈谈使用机器学习具体可以做什么?整体而言,我们使用机器学习关注的任务主要分为两大类:分类和回归。
分类
分类任务上面我们其实已经提到,比如一张图片识别出 是猫是狗,一封邮件是否是垃圾邮件等等,也就是我们最终机器学习算法要解决的任务是将我们给定的数据进行一个分类,对分类任务进一步细分可以分为:二分类 、多分类 。
二分类
- 判断邮件是否是垃圾邮件
- 银行发给客观信用卡是否有风险
- 判断某只stock是涨还是跌
多分类
-
手写数字识别0-9
-
判断发放给客户信用卡的风险评级
分类任务看起来我们要获得的结果是十分明确的,其实很多看似很复杂的任务都可以转化为多分类任务 。比如下围棋,棋盘上可以落子的地方是有限的,所以每一步机器要做的就是根据现有棋盘信息选择一个地方进行落子,可以转化为一个分类任务。包括现在爆火的无人驾驶,车辆根据车身自带的摄像头传感器收集的信息,每一步要做的就是控制方向盘向左还是向右打多少个角度,油门和刹车踩的深浅是多少个级别(可以设置10个级别).

注意:这些问题可以转化为多分类问题,但不代表使用多分类的方式来解决这些问题是最好的解决方案。
像一些算法逻辑回归、SVM只支持二分类任务,但是多分类的任务都可以转化为二分类的任务,同时有些算法天然可以完成多分类任务。
回归
还有一类数据是下面这个样子,这组数据特征有4个:面积、年龄、数量、距离,与分类问题的标签明显不同的是,此时对应的标签是一个价格,是一个连续数字的值,而非一个类别 ,这类任务就叫做回归任务,它的特点就是最终结果是一个连续的值。
| 房屋面积 | 房屋年龄/年 | 卧室数量/间 | 最近地铁站距离/km | 价格/万元 |
|---|---|---|---|---|
| 80 | 3 | 1 | 10 | 300 |
| 120 | 8 | 3 | 5 | 500 |
| 200 | 5 | 4 | 12 | 700 |
回归任务的一些例子像预测房屋价格、分析商场能卖多少货物、预测股票价格等等。
同样有些算法只能解决回归问题,有些只能解决分类问题,而有些算法既能解决回归问题也能解决分类问题(思考一下有哪些)。同时一些情况下回归任务也是可以简化为分类任务,比如预测学生成成绩 可以 转化为 给学生一个评级(A、B、C等),包括上面谈到无人驾驶方向盘转的角度是个连续数值原本也是个回归问题,但是通过设定成几个固定的角度 就简化成了一个分类任务。
这里最后说明一下,机器学习主要解决的分类和回归两大类问题主要指的是监督学习 ,实际上机器学习还可以解决很多别的问题(聚类降维等),下面将会介绍一些机器学习方法的分类即什么是监督学习、非监督学习?
机器学习方法的分类
上面介绍了机器学习可以处理的两类任务–分类和回归。这是从机器学习可以解决的问题的角度进行分类的,而不是从机器学习算法本身进行分类的。如果我们把目光放在机器学习算法上,整体上我们可以把机器学习的算法分为监督学习、非监督学习、半监督学习和增强学习 。
监督学习
监督学习的主要特点就是我们给机器的训练数据是拥有“标记”或“答案”的。比如上面我提到的iris数据集,每条数据最后有一个标签代表其属于哪一类别,又如上面房屋数据最后的价格。这里“监督“的意思就是我们人类已经针对给机器的数据进行了正确答案的划分,这种正确答案的划分本身就称为一种监督的信息。
实际生活中很多的学习过程都是监督学习的过程,比如银行已经积累了一定的客户信息和他们信用卡的信用情况;图像拥有标定信息;医院积累了一定的病人信息以及他们最终是否患病的情况;房屋市场已经积累了房屋的基本信息和最终成交的金额。根据这些已有的”监督“信息我们能训练模型 预测出一个新的、未知的房屋价格或者判断出是否患病。
非监督学习
与监督学习相反,非监督学习的主要特点就是给机器的训练数据没有任何”标记“ 或者 ”答案“。正因这种特性,非监督学习可以进行聚类、降维、异常检测等等。
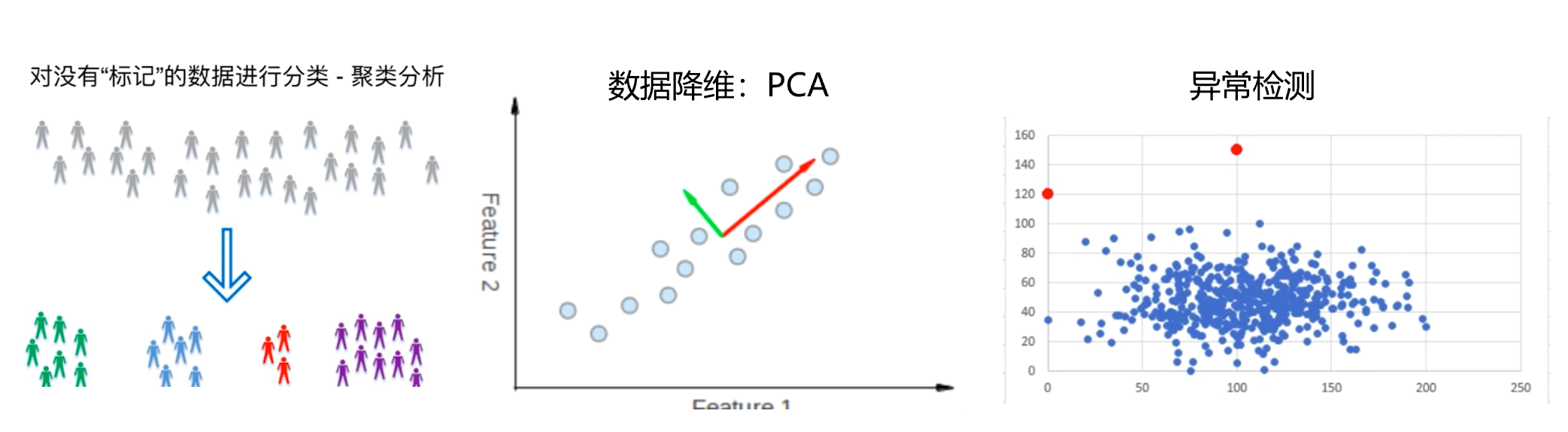
半监督学习
半监督学习的主要特点就是给机器的数据中一部分数据有”标记“或者”答案“,另一部分数据没有。这种情况在生活中反而是更常见的,因为各种原因都有可能产生标记的缺失。 而半监督学习通常就是监督和无监督的结合,先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测。
增强学习
根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。此时算法通常叫做Agent,Agent在一轮又一轮行动和反馈中逐渐增强自己的智能,所以叫做增强学习 。显然增强学习是非常适合机器人。
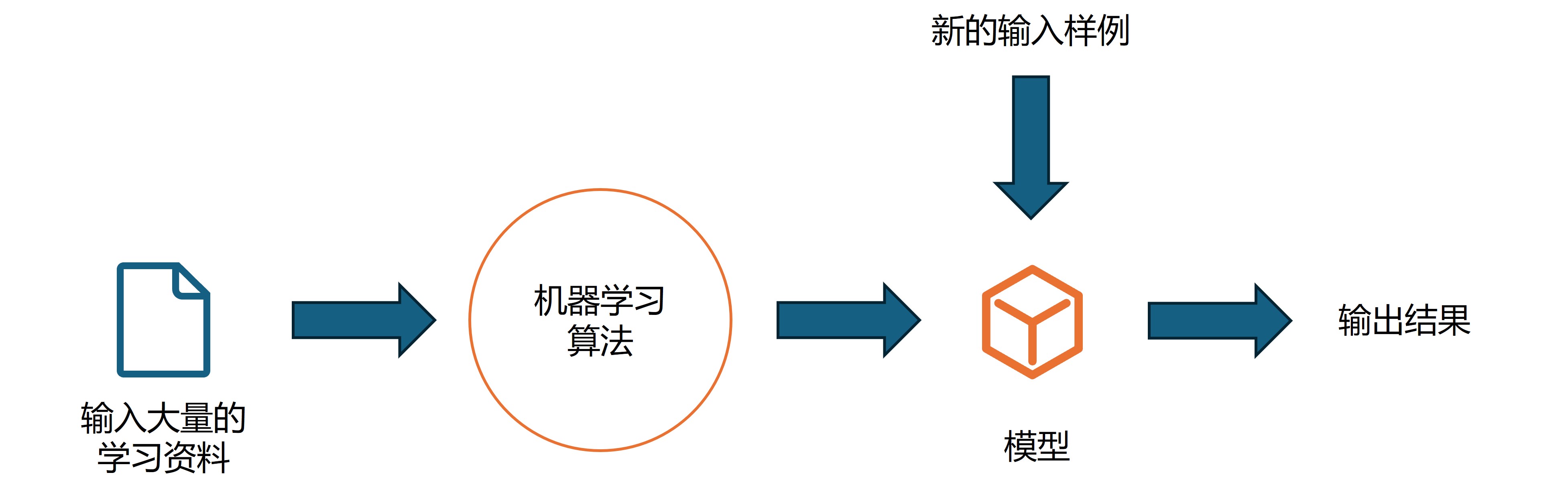
机器学习的其他分类
在线学习和批量学习(离线学习)
批量学习Batch learning也叫离线学习,指的是首先收集一定量的数据,然后将这些数据送给算法 训练出模型,训练出模型后可以直接将模型投入到生产环境中。在具体应用中可能会有新的样例投入模型得到结果,这个过程中模型不会再发生任何变化了。
- 优点:简单
- 问题:如何适应环境变化?解决方案:定时重新批量学习
- 缺点:每次重新批量学习运算量大,在某些环境变换非常快的情况下,甚至不可能的。
在线学习
- 优点:及时反映新的环境变化
- 问题:新的数据带来不好的变化?这些新数据可能因为设备等等原因是异常数据,会对模型进行破坏。
- 解决方案:需要加强对数据进行监控
参数学习
- 假设数据服从某种固定形式的分布,用有限数量的参数描述模型,参数数量与数据量无关
非参数学习
- 不对模型进行过多假设
- 非参数不代表没参数
一些思考
数据即算法?在机器学习和深度学习领域,可以发现当数据量大到一定程度时,算法与算法之间的准确率差别并不大,算法似乎并不那么重要了。同时现在大多数机器学习、深度学习算法都是由数据驱动的,高度依赖数据本身的质量,这也使得大多研究专注于收集更多更高质量的数据,看起来数据为王。但也有些领域比如围棋界的AlphaGO Zero 从0开始,它本身没有被喂给任何数据,数据都是靠算法产生的,似乎打破了数据即算法这种说法,依然算法为王。当然不排除围棋本身的特殊性在这里,这个结论不对任何一个领域都适用,但是这突破告诉我们算法本身依然很重要的,再好的数据也要高效、优秀的算法作为辅助才能最大程度发挥数据的作用。但是短时间内机器学习大部分任务依然是数据驱动的, 我也相信不久的未来会出现算法领域的突破。
如何选择机器学习算法? 机器学习有很多的算法,但它们解决的问题都是差不多的,比如监督学习的分类问题和回归问题,那么如何选择算法呢?有一种思想叫做 奥卡姆的剃刀:如无必要,勿增实体 ,简而言之就是在解释或建模时优先选择最简单、假设少的方案。 即简单的就是好的 ,同时我们也要定义何为”简单“。





