
一文理解Transformer
Preface
很开心这周先是回重庆了,趁着有空于是便顺着以前的好奇心接着读了Transformer一文.Transformer作为当今LLM的基座模型,我认为每一个入行ai的学者都绕不过这关,熟悉理解Transformer架构以及注意力机制计算也算是通向大厂的一块敲门砖。很难想象这篇开山之作是在2017年谷歌团队发表的,转眼间也是8年已过,可以预见的是Transformer的应用层面还在不断延申,我初读这篇论文时遇到了很多难题,不过经过大量的资料查找以及知识补全,我现在可以说自己对Transformer有了一定的认识和了解,因此我写下这篇博客既对我自己的理解进行整理归纳,同时也希望读到能够帮助读者理解Transformer。
论文阅读:Attention is all you need
ABSTRACT
这篇论文写于2017年,在这之前主流的序列模型都是基于RNN或者CNN的,性能最好的模型也只是将注意力机制引入到了RNN中。而这篇论文提出了一个全新的网络架构—Transformer ,Transformer完全基于注意力机制,没有用到任何CNN和RNN.同时作者表示Transformer这种架构在两个机器翻译任务中优于现有方法,训练时间很短。
Introduction and Background
在 Transformer 提出之前,传统的循环神经网络(RNN)曾被广泛认为是处理序列任务的最好方法。然而,RNN 在结构上具有显著的串行特性:其每一时刻的隐状态依赖于前一时刻的隐状态,因此难以实现并行计算。同时,当输入序列较长时,RNN 往往面临长期依赖问题,导致模型难以捕捉远距离的信息。为了解决这些问题,注意力机制被提出,通过计算输入中所有位置的加权和,使模型能够直接关注重要的信息片段,从而在处理长文本任务时更为有效。但注意力机制在最初仍是与 RNN 结合使用,仍未彻底解决并行计算的难题。
总结来说,Transformer 提出正是基于两个关键动机:一是想要彻底摆脱 RNN 的串行结构,实现模型在训练时的高度并行化;二是将注意力机制作为核心结构,从而更好地建模序列中任意位置之间的关系。
Attention
我们先来看下面一张图,我相信大家看到下面图的一瞬间肯定看到的是“什么是注意力机制?“这几个红字,而非图片白色背景。同样我们人类大脑会接收到源自视觉、听觉、触觉等多种感官的诸多信号,然而我们并非会均等处理这些信息,而是倾向于关注其中对于当前任务最为相关或者最为突出的部分,这就是注意力。

然后看下面一张图片,我们来做一个深度学习常用的VQA ( Visual Question Answering) ,如果根据这张图片问你一个问题”这个人在干嘛“,我相信我们人一眼就能看出这个人在打网球,其实再仔细分一下我们不自觉的关注到了图中的红框区域球拍和网球,从而得出了这个结论。所以我们研究注意力就是同样想要使我们的模型能够关注到这种揭示答案的区域。

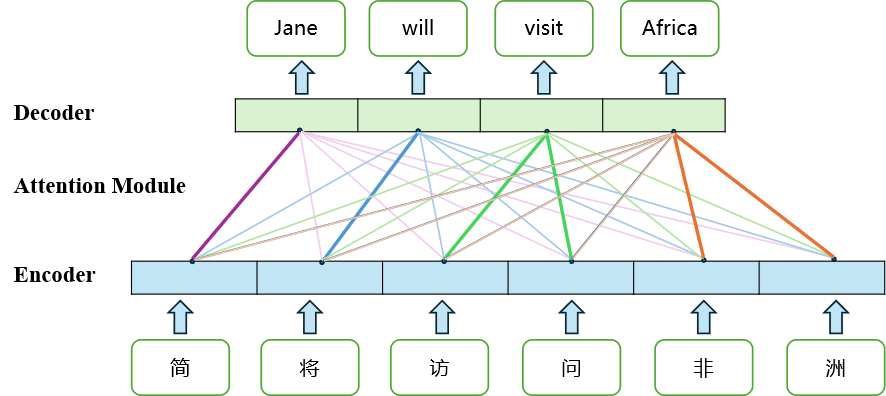
接着看看注意力机制在机器翻译中的用法,比如下面图中的中翻英,我们首先会将输入进行Embedding转换成向量,然后每一步解码的时候我们会对所有输入计算一个Attention weight,就像图中颜色的深浅,可以看出来Jane 更关注中文的”简“,而其他不相关的词语相应的权重就更小。
注意力如何计算?
注意力机制从计算机的角度来看本质是一个寻址过程。
上面的讲述应该让你对注意力的概念有个比较清楚的认识,但是这里面的注意力是如何计算的呢?
我来举个简单的的例子,假设你今天想找一本书看,但你并没有明确想看哪一本。于是你去问朋友:“有没有推荐的小说?”这时候你朋友会根据你以往的阅读兴趣(query),结合他们手头的书单(key),推荐你一些书(value)。
我们不妨先把你的Query"有没有推荐的小说"转化为一个向量比如:[0.8, 0.1, 0.1] ,这三个维度表示你很喜欢小说(第一维),偶尔看看历史或科技类(第二、三维)。下面是朋友推荐的书单,这三个维度同样我们用向量表示,三个维度含义也表示(小说、历史、科技).
1 | Books = { |
我们用向量点积来计算你兴趣Query和每本书Key的相似度:
1 | dot([0.8, 0.1, 0.1], [0.9, 0.1, 0.0]) = 0.8*0.9 + 0.1*0.1 + 0.1*0 = 0.73 |
从而得到一组相似度分数(即 attention logits):
1 | [0.73, 0.24, 0.08, 0.59] |
进行一个softmax得到一个0-1的权重:
1 | softmax([0.73, 0.24, 0.08, 0.59]) ≈ [0.39, 0.20, 0.17, 0.35] |
从这个结果我们不难得出,根据你的Query朋友推荐的书中《三体》应该最受你欢迎,权重为 0.39,《解忧杂货店》其次0.35,历史类和科技类的推荐度相对低一些。
Scaled Dot-Product Attention
论文中将这种注意力计算叫做”缩放点积注意力“,它的公式是:
如何理解这个公式呢?不妨带入一下刚刚的例子:
- 你的问题(“想看小说”)是 Query,我们用一个向量**[0.8,0.1,0.1]**表示;
- 朋友书单中每本书的标签(类型、风格等)是 Key,我们同样用向量表示;
- 每本书本身是 Value;
- 朋友根据“这本书跟你口味相不相近”打分,作为 注意力权重 ,也是我们的QK点积计算后再通过一个Softmax;
- 最后,把这些书的推荐度加权求和,得出综合推荐结果。
但是可以发现这个公式中还除了一个 ,这是因为,softmax在绝对值较大的区域梯度较小,梯度下降的速度比较慢。因此,我们要让被softmax的点乘数值尽可能小。而一般在dk较大时,也就是向量较长时,点乘的数值会比较大。除以一个和dk相关的量能够防止点乘的值过大。刚才也提到,$QK^T $本质上是在算query和key的相似度。而算相似度并不只有求点乘这一种方式,还有加性、余弦相似度等等方式。
Self-Attention
什么是自注意力?其实就如名字的含义自己对自己做注意力计算。比如在一个句子时,自注意力机制使模型能够关注输入中与该单词密切相关的其他单词。例如,“Ball”与"blue"和“holding”密切相关。另一方面,"blue"与"boy”无关。

Transformer主要采用Self-Attention来使输入序列的每个单词和其他单词关联起来,还有下面这张图片中,左边这张图中it指代的是“cat”,而右图这种语境中it指代的是“milk”.
这里我希望大家能体会到自注意力的”自“其实就是自己与自己计算,就像这个图中,通过自注意力可以得到it在语境中具体意思,在注意力公式中的具体表现就是Q,K,V是源自同一个输入。

所以自注意力的有一个很典型的特点就是自己对自己计算注意力,对应到公式中理解也就是Q,K,V是同一输入的 。
Model Architecture
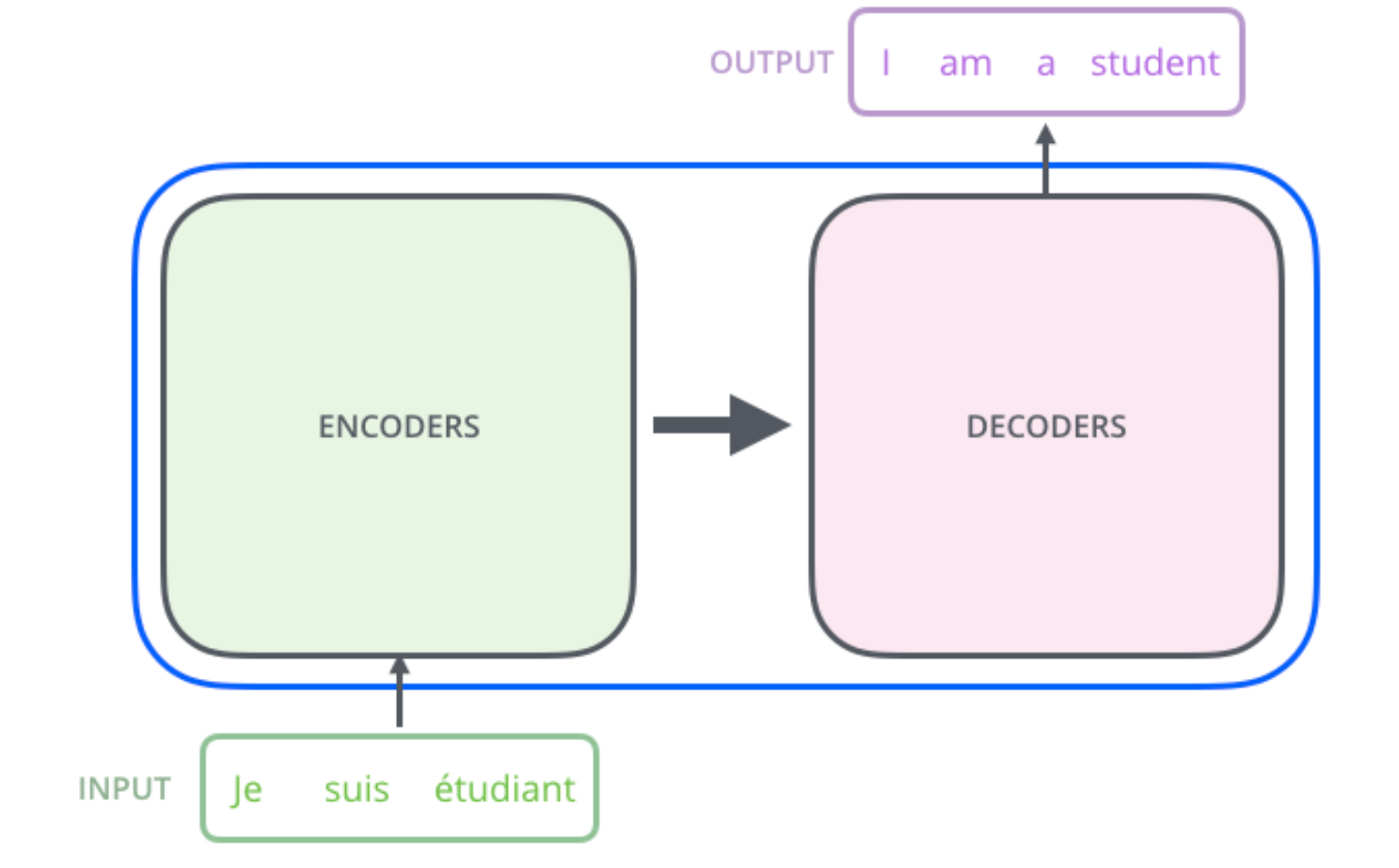
这里我先不去介绍论文给出的Transformer模型架构图,我们先从一个High-level去看Transformer模型架构如下图所示,它的输入是一个Sequence,输出也是一个Sequence.

我们接着尝试打开这个结构,可以发现Transformer由一组编码器和一组解码器组成,所以Transformer本质上还是沿用了Encoder-Decoder结构。
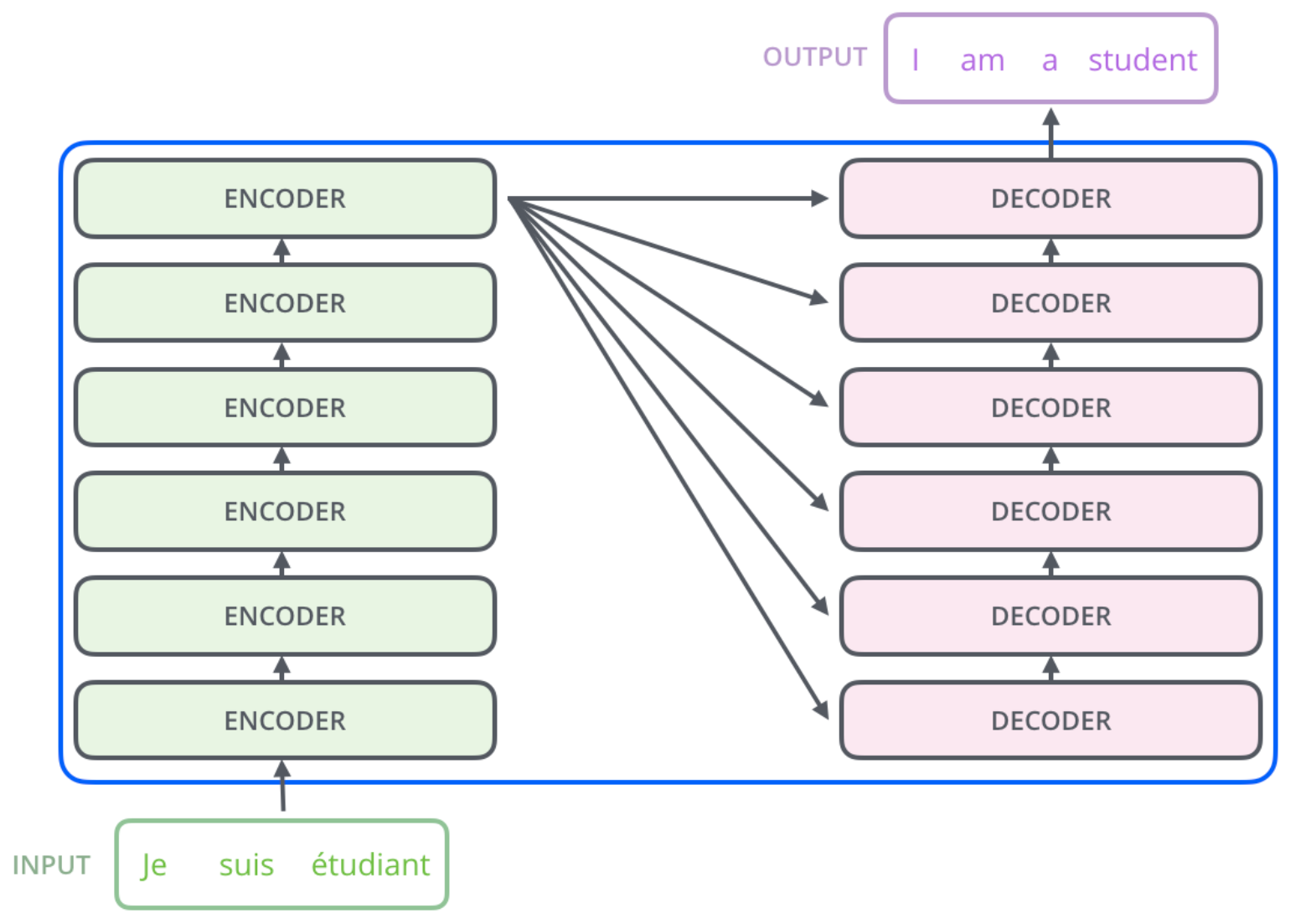
细心的同学可以发现我上面表述用到了“一组”而非“一个”,图中的Encoders和Decoders而非Encoder和Decoder也暗示了这一点,所以我们再次细化Transformer结构,可以发现它的编码组件是一组编码器的堆叠,而解码组件则是一堆数量相同的解码器。每个编码器和解码器的结构都是相同的,但是它们并不共享权重。
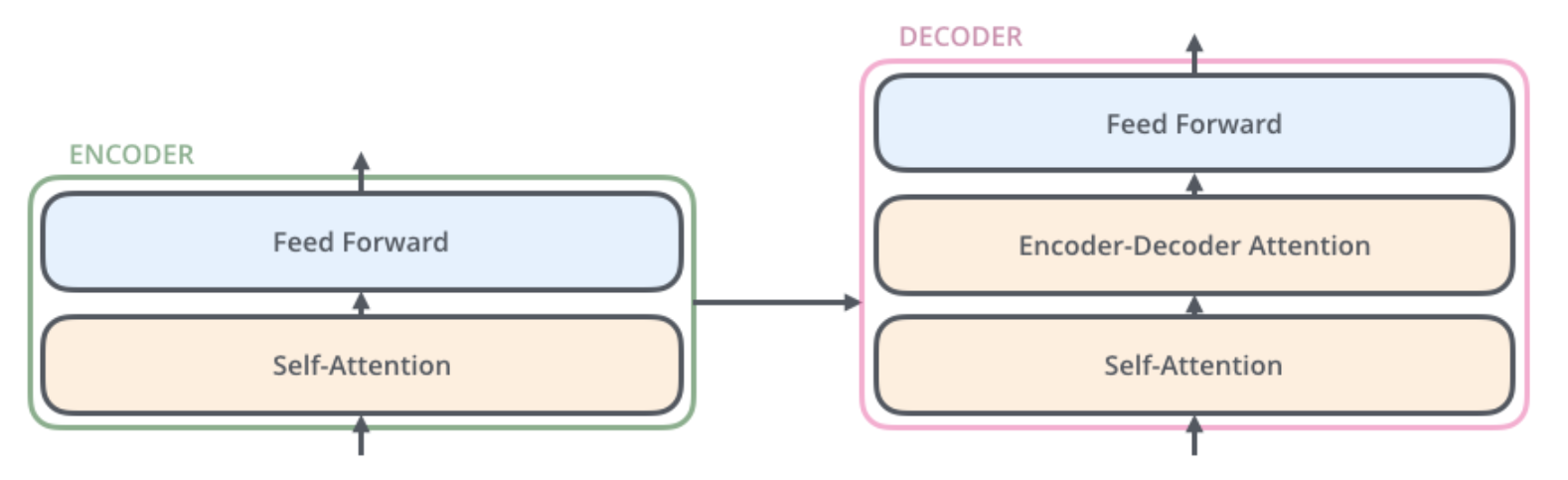
接下来我们先看看每个编码器和解码器的具体结构(如下图)。
- 编码器:主要包含两个子层自注意力层和前馈网络层,自注意力层主要计算序列中不同单词之间的关系,自注意力我们将在后面详细讨论一下。
- 解码器:主要包含自注意力层和一个Encoder-Decoder注意力层以及前馈网络层
Data Flow in Transformer
接下来我们完整的看一遍输入数据如何在Transformer中一步一步转换的。
1.Embedding and Positional Encoding
Embedding 是 Transformer 的第一步,它的作用是将原本离散的token转换成连续的向量表示,让模型能够理解和处理这些信息。每个词都会被映射为一个具有语义意义的向量,向量之间的距离和方向可以反映出词语之间的相似关系。
无论是RNN还是CNN,都能自然地利用到序列的先后顺序这一信息。然而,Transformer 自身不具备“顺序感知能力”,它无法知道词与词之间的先后顺序。因此,我们还需要加入 位置编码(Positional Encoding),为每个词向量注入位置信息,让模型能够识别出词语在句子中的排列顺序。(后面会详细讲一下位置编码,这里我们只需要知道对输入Embedding的同时还加上了位置编码)
2.Self-Attention and Feed Forward
接着我们会将Embedding和Positional Encoding后的输入序列输入编码器,具体来说先会经过一个自注意力层和一个前馈网络层,然后将输出传给下一个堆叠的编码器。
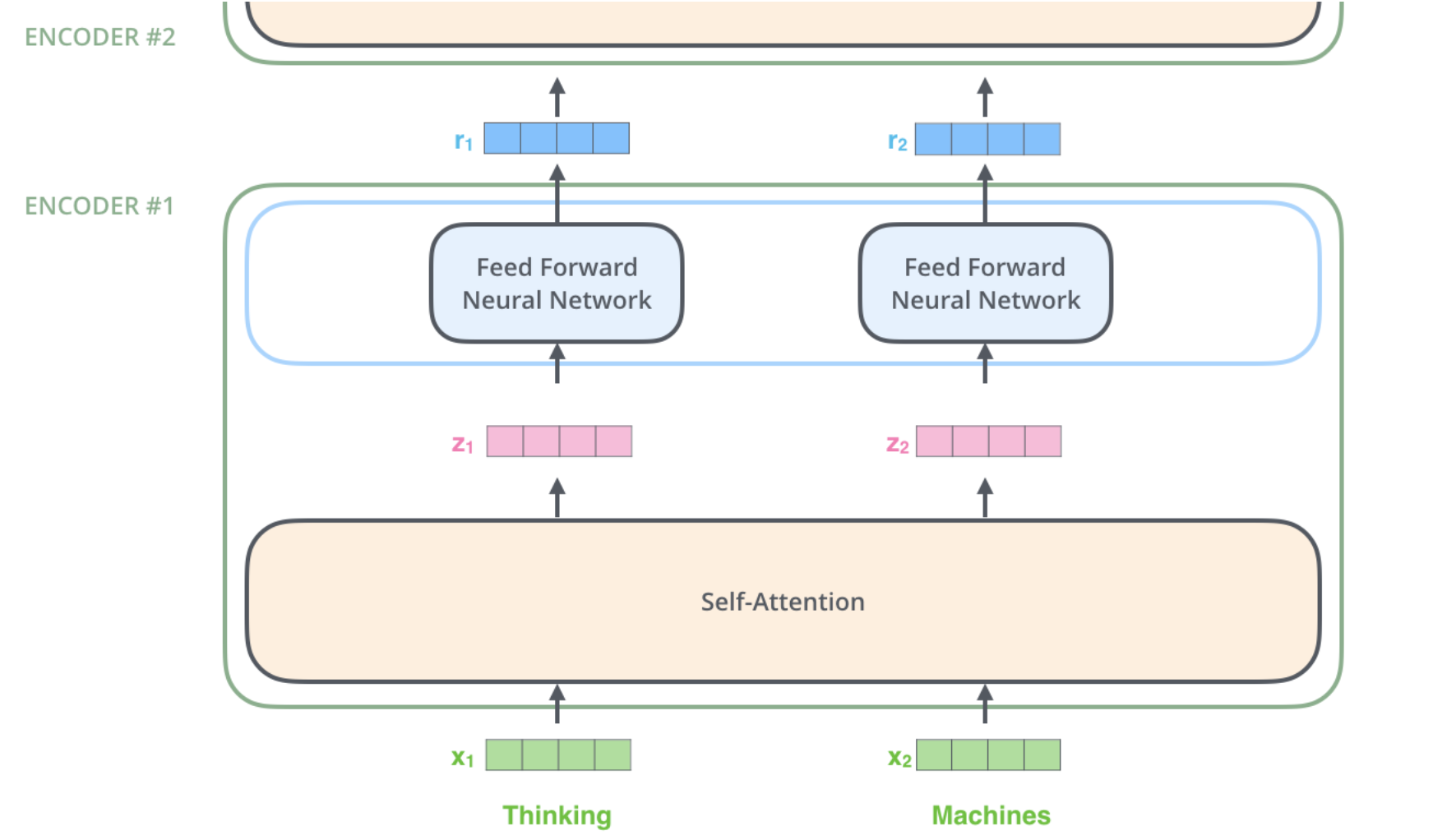
这里我们再次详细解剖一下Self-Attention是如何计算的?如下面图所示,计算自注意力机制的第一步是从编码器的每个输入向
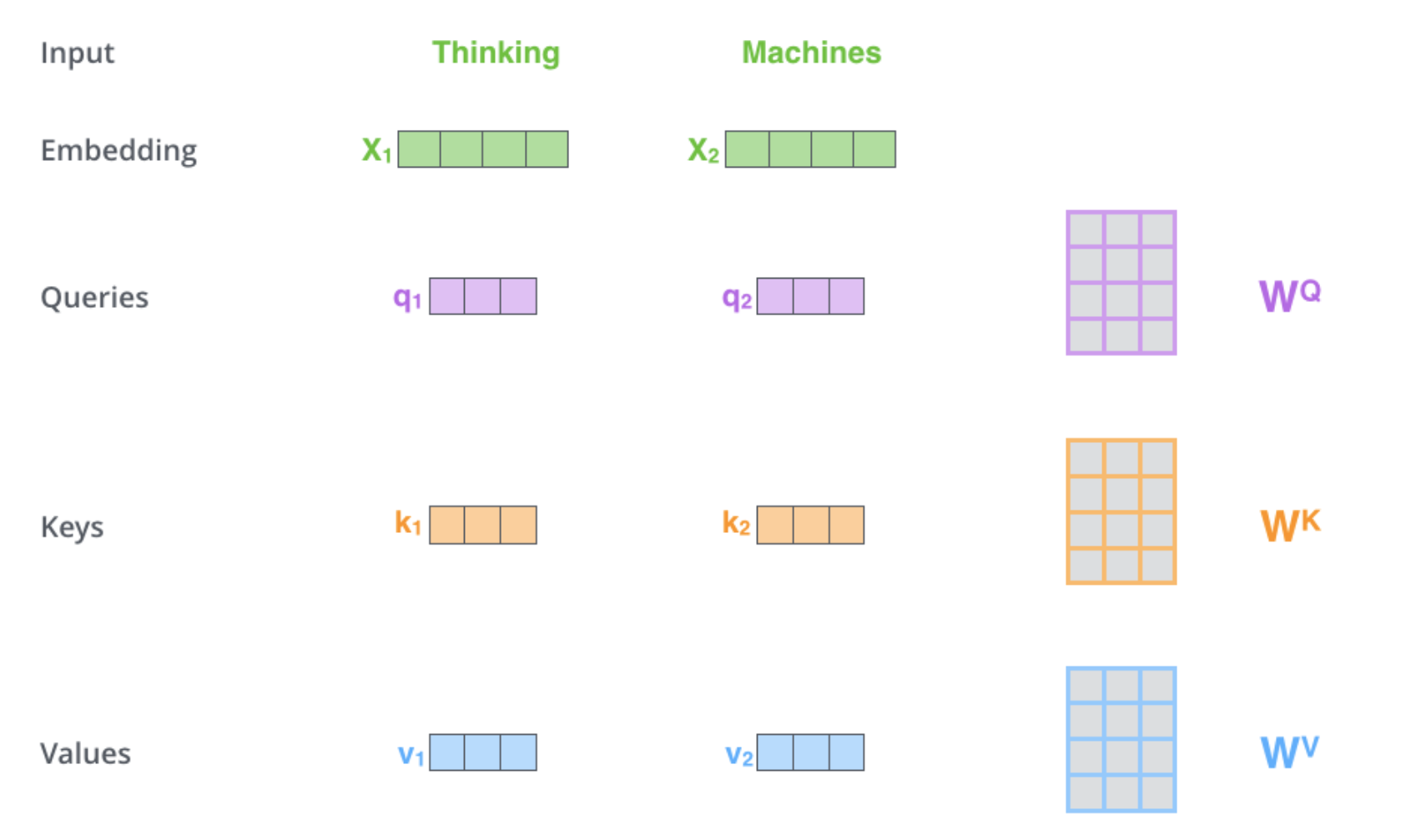
量创建三个向量。因此,对于每个单词,我们创建一个查询向量、一个键向量和一个值向量。这些向量是通过将嵌入向量乘以我们在训练过程中训练的三个矩阵而创建的。
计算自注意力机制的第二步是计算分数。假设我们正在计算本例中第一个单词**“Thinking”**的自注意力机制。我们需要根据这个单词对输入句子中的每个单词进行评分。分数决定了在特定位置对单词进行编码时,对输入句子其他部分的关注程度。
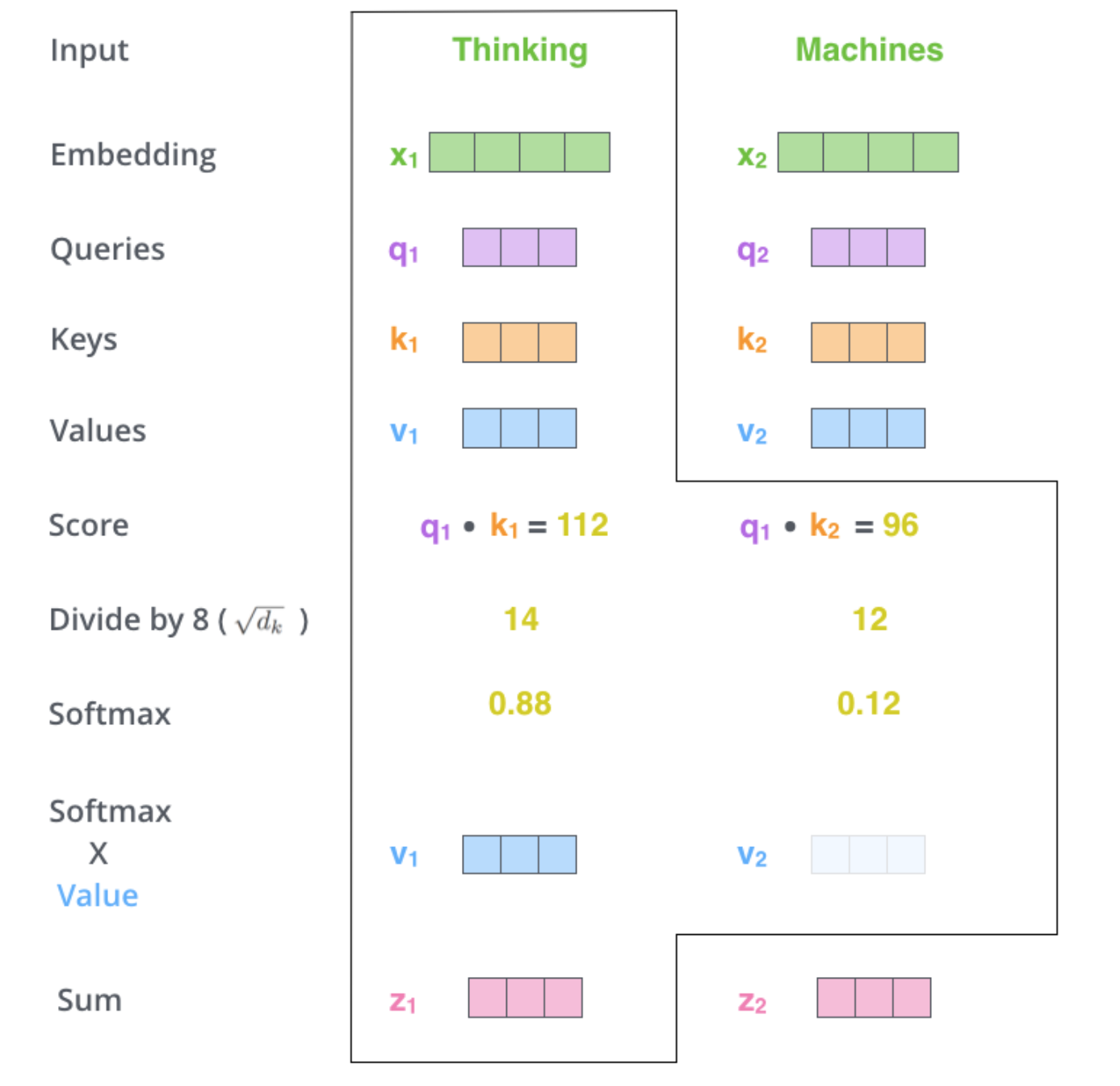
得分是通过对查询向量Query与我们要评分的相应单词的键向量Key进行点积计算得出的。因此,如果我们处理位置#1的单词的自注意力机制,第一个得分将是q1和k1的点积。第二个得分将是q1和k2的点积。第三步和第四步是将得分除以8(论文中使用dk=64,这会导致梯度更稳定。这里可能还有其他可能的值,但这是默认值),然后将结果传递给Softmax运算。Softmax会对得分进行归一化,使它们全部为正数,并且总和为1。第五步是将每个值向量乘以softmax分数(为求和做准备)。这里的直觉是保持我们想要关注的单词的值不变,并掩盖不相关的单词(例如,通过乘以0.001这样的小数).第六步是将加权值向量相加。这将产生自注意力层在此位置的输出(对于第一个词).
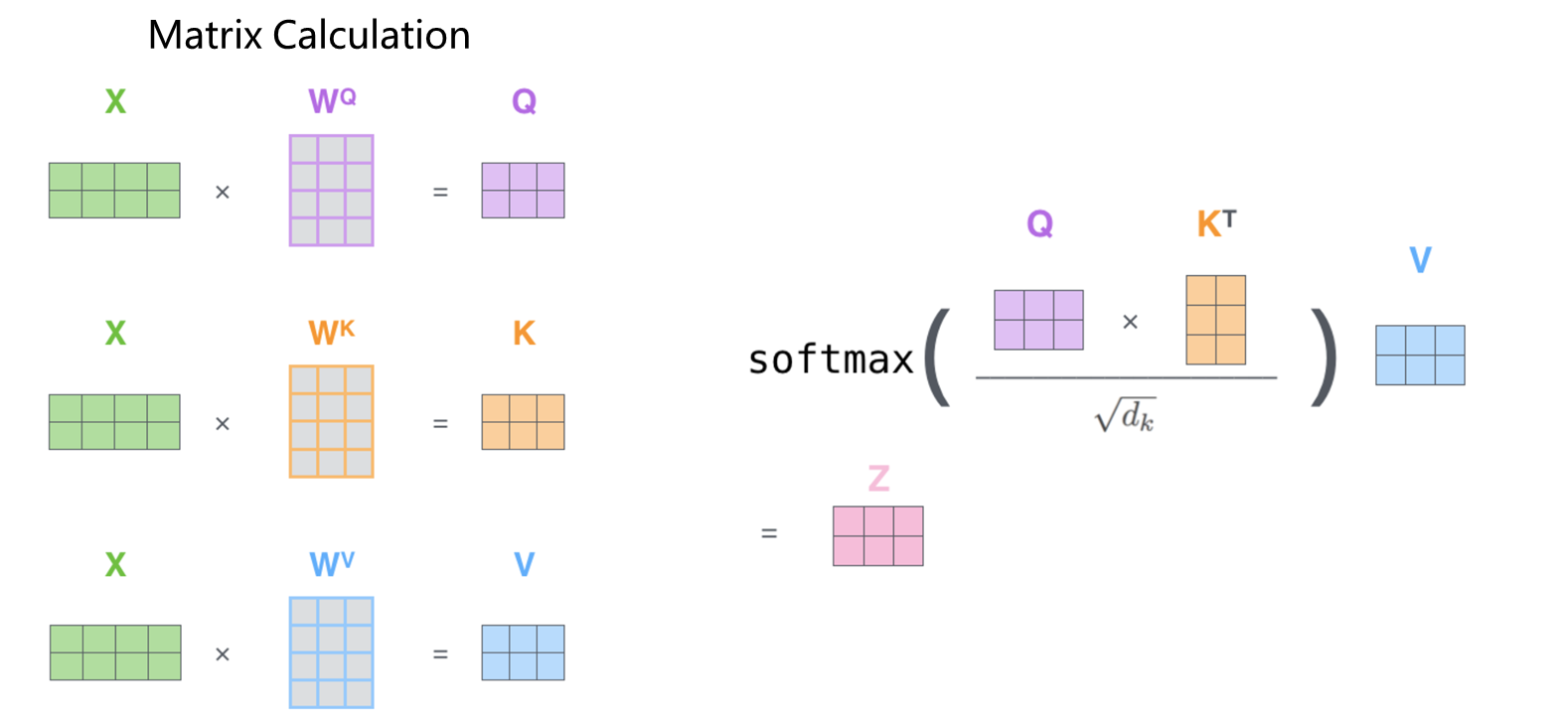
自注意力计算到此结束。最终得到的向量可以发送到前馈神经网络。然而,在实际实现中,为了加快处理速度,这个计算是以矩阵形式进行的。既然我们已经了解了词级计算的直观原理,现在我们来看一下这个矩阵。
Matrix Calculation
上面为了方便讲解,我们是采用了单个向量计算的图示,实际应用中计算通常采用矩阵的形式。具体如下,第一步我们将嵌入后的X分别与我们的 矩阵相乘得到Q,K,V,第二部也是用得到的矩阵带入到注意力计算的公式中去得到z.
3.Multi-Head Attention
多头注意力机制(Multi-head Attention)使模型能够同时关注来自不同表示子空间的不同位置的信息。而单一注意力头则容易由于取平均而削弱这种能力。
在 Transformer 中,为了让模型从多个角度理解信息,作者引入了“多头注意力”机制:
- 将 query、key、value 各自线性变换成多个子空间(头)
- 每个子空间独立计算注意力
- 最后把各头的输出拼接起来,再做一次线性变换
它扩展了模型关注不同位置的能力。没错,在上面的例子中,z1包含了其他所有编码的一点点,但它可能主要由实际的单词本身决定。如果我们要翻译像“这只动物因为太累了而没有过马路”这样的句子,那么知道“它”指的是哪个词会很有用。
它为注意力层提供了多个“表征子空间”。正如我们接下来将看到的,多头注意力机制不仅拥有一组查询/键/值权重矩阵,而是拥有多组(Transformer使用8个注意力头,因此每个编码器/解码器最终都有八组权重矩阵)。每组权重矩阵都经过随机初始化。训练结束后,每组权重矩阵都会用于将输入嵌入(或来自底层编码器/解码器的向量)投影到不同的表征子空间。
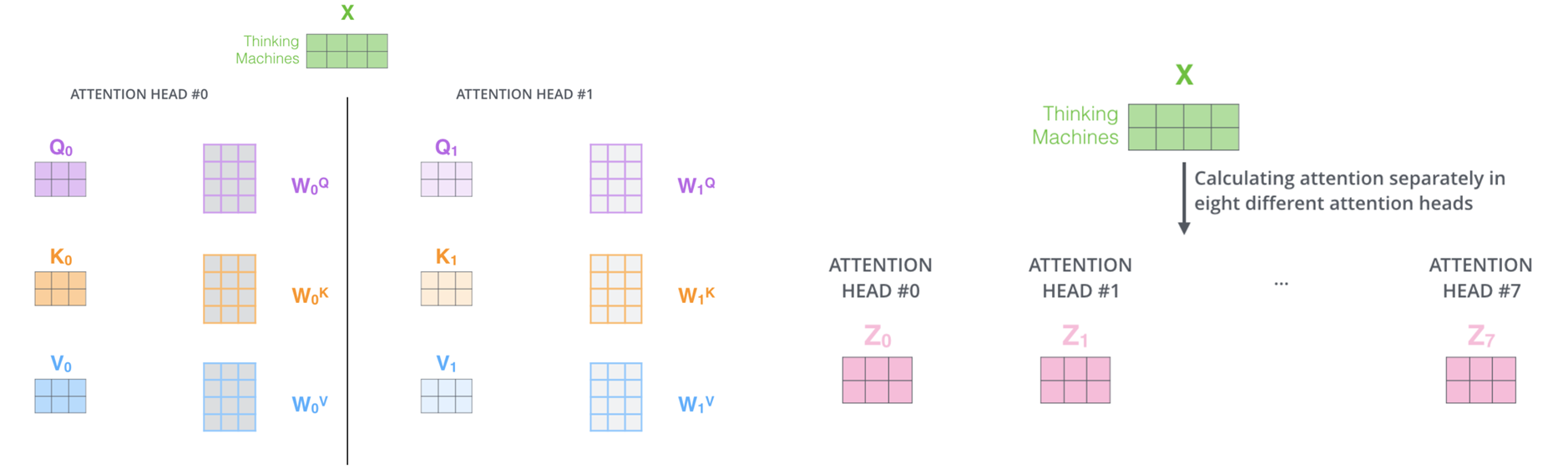
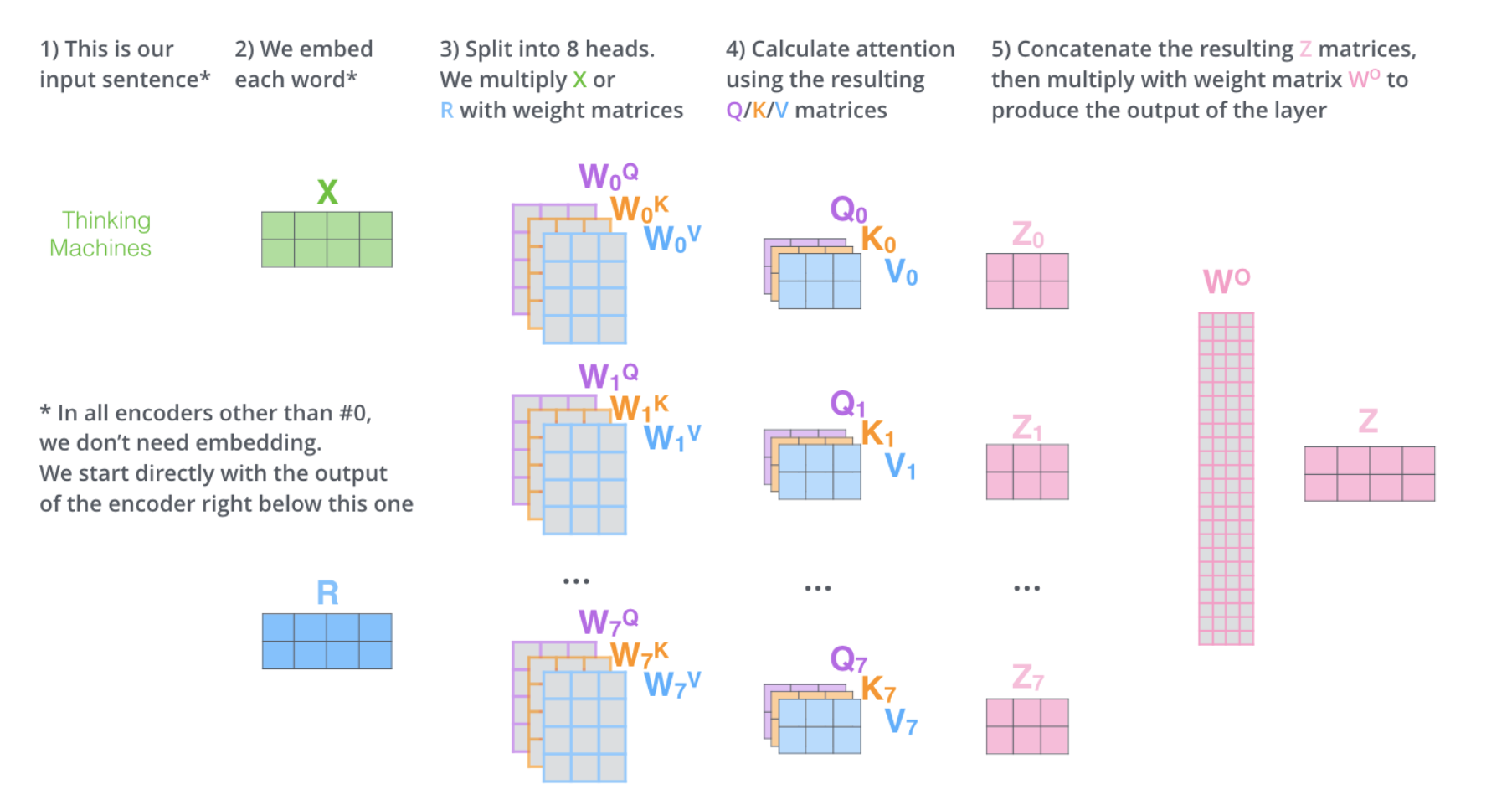
如果我们进行上面概述的相同的自注意力计算,只需使用不同的权重矩阵进行8次不同的计算,我们最终会得到8个不同的Z矩阵.这给我们带来了一些挑战。前馈层不需要八个矩阵它只需要一个矩阵(每个单词一个向量)。所以我们需要一种方法将这八个矩阵压缩成一个矩阵。怎么做呢?我们将这些矩阵连接起来,然后乘以一个额外的权重矩阵WO。

上面就是多头注意力的主要内容,总结成下面一个视图。
4.The Residuals
讲完核心的自注意力计算以及多头注意力 ,顺便补充一下Encoder和Deocder架构中的一个细节,每一Encoder都包含两个子层.第一个子层是多头自注意力机制(Multi-Head Self-Attention),第二层是逐位置的全连接前馈神经网络(Position-wise Feed-Forward Network)。每个子层外部我们都引入了残差连接,然后再进Layer Normalization。也就是说,每个子层的输出为:LayerNorm(x + Sublayer(x)).
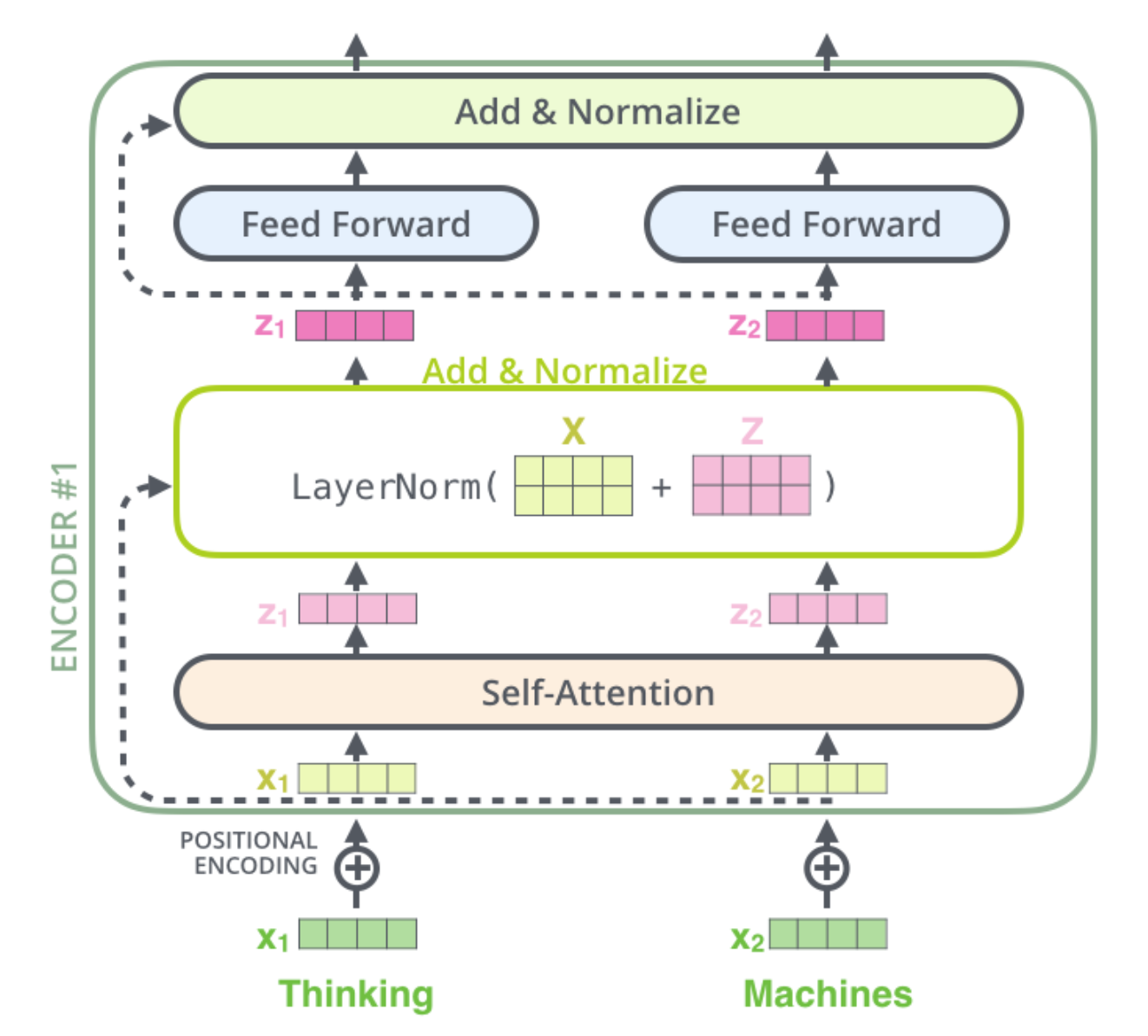
同样对于Decoder的每个子层也同样采用了残差连接的方式。
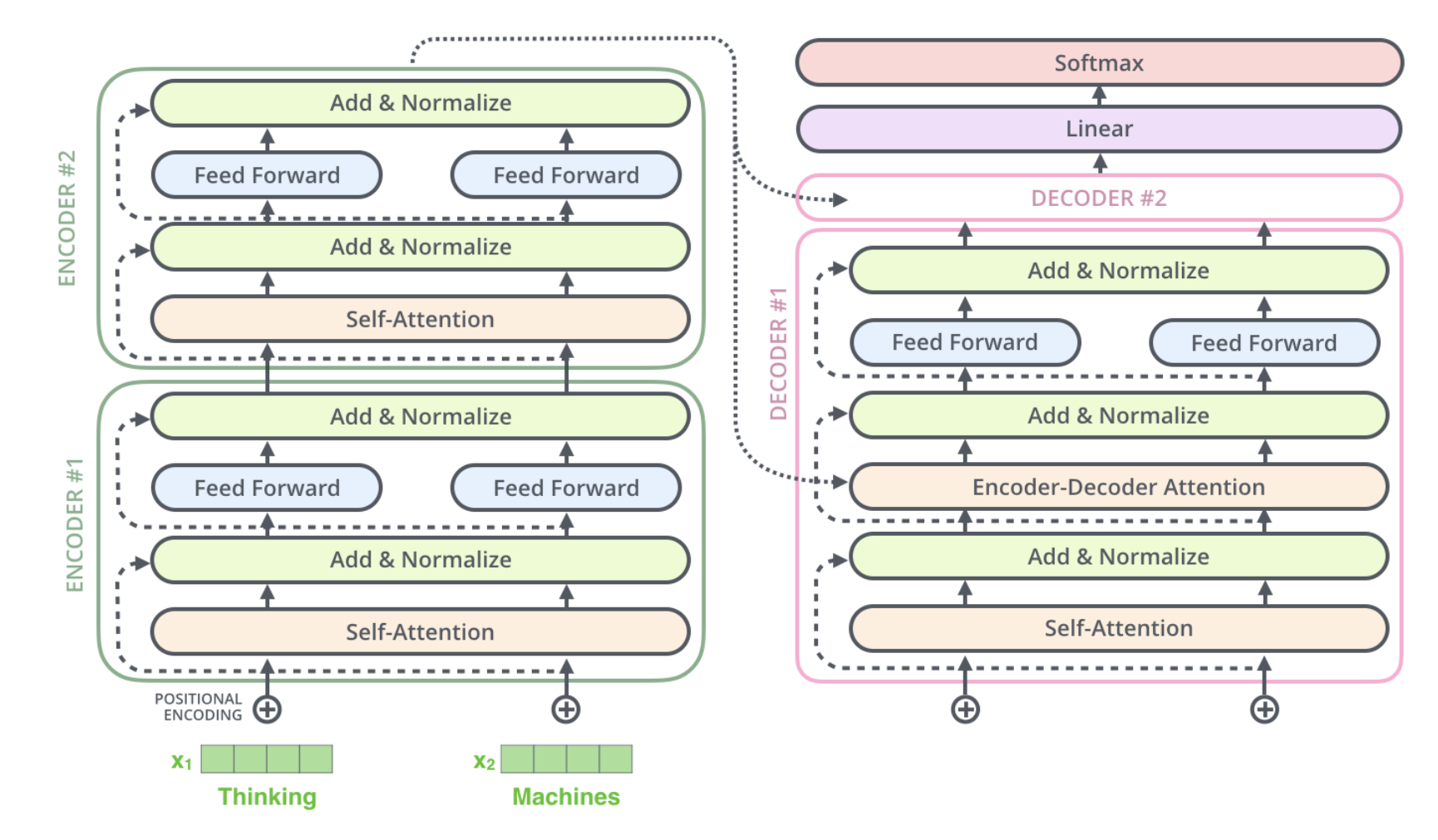
5.Decoder
顶部编码器的输出会被转换成一组注意向量K和V。每个解码器在其”编码器-解码器注意”层中使用这些向量,这有助于解码器将注意力集中在输入序列中的适当位置。具体的工作流程如下图所示:
![]()
我们最终会将解码器输出的向量通过一个Linear层即全连接层进行投影。假设我们的模型知道10000个独特的英语单词(也就是我们模型的“输出词汇”),这些单词是从训练数据集中学习到的。这将使logits向量宽度达到10000个单元格各一—每个单元格对应一个独特单词的得分。这就是我们对线性层之后的模型输出的解释。然后,softmax层将这些分数转换为概率(所有分数均为正,加起来为1.0)。选择概率最高的单元格,并生成与其关联的单词作为此时间步的输出。
