Preface
最好先读懂Transformer再来看这个实现,这次我没有具体讲每一行代码,主要是记录这次实现https://github.com/sukiAme7/G2P/tree/main
项目介绍
G2P介绍
Grapheme-to-Phoneme(G2P)转换 是自然语言处理 和语音处理中的基础任务,其目标是:
将一个词的拼写(字母/字素)序列转换为其发音(音素)序列。
比如下面的例子:
输入(字母序列)
输出(音素序列)
cat/k/ /æ/ /t/
physics/f/ /ɪ/ /z/ /ɪ/ /k/ /s/
G2P一些应用:
文本转语音(TTS)
将输入的文字转换成准确的发音(音素序列),供声学模型合成语音。
📌 例如:
1 2 3 输入:knowledge G2P 输出:/n/ /ɑː/ /l/ /ɪ/ /dʒ/ 语音合成模型再将其转为语音波形。
语音识别(ASR)中的词典构建
用于构建 发音词典 (Lexicon),将语音信号与文字对应起来。
对于未登录词(OOV),G2P 可以自动生成其发音,补全词典。
📌 例如:
1 2 ASR 模型需要将音频中的 /s/ /t/ /uː/ /d/ /ə/ /n/ /t/ 匹配到 "student" G2P 提供 student → /s/ /t/ /uː/ /d/ /ə/ /n/ /t/
语言学习/教学工具
G2P 模型可用于语言学习软件,展示正确的词语发音。
数据集
cmudict介绍
cmudict,全称是 CMU Pronouncing Dictionary ,是由卡内基梅隆大学发布的一套免费开源的英文发音词典,广泛应用于语音合成(TTS)、语音识别(ASR)、G2P 模型训练等任务。它的核心作用是为每个英文单词提供标准的音素发音,用于将拼写(字母序列)映射为发音(音素序列)。
数据格式如下:
1 HELLO HH AH0 L OW1 # 首先是单词 然后 是它的 发音音素
对于多音词,词典会列出多个发音,用 (1), (2) 等编号区分,比如:
1 2 READ R EH1 D READ(1) R IY1 D
整个词典包含约 13 万个单词 ,覆盖了大多数常见和部分专业词汇,本次项目我是选择用这个数据进行训练。
CMUdict数据链接 :https://github.com/cmusphinx/cmudict
数据预处理
在上述链接下载一个名为cmudict.dict的文件,该文件即为我们所要用的数据。然后打开这个文件观察一下数据的样式,可以发现每一行数据是一个单词 和它对应的发音:
比如:
1 abnormal AE0 B N AO1 R M AH0 L
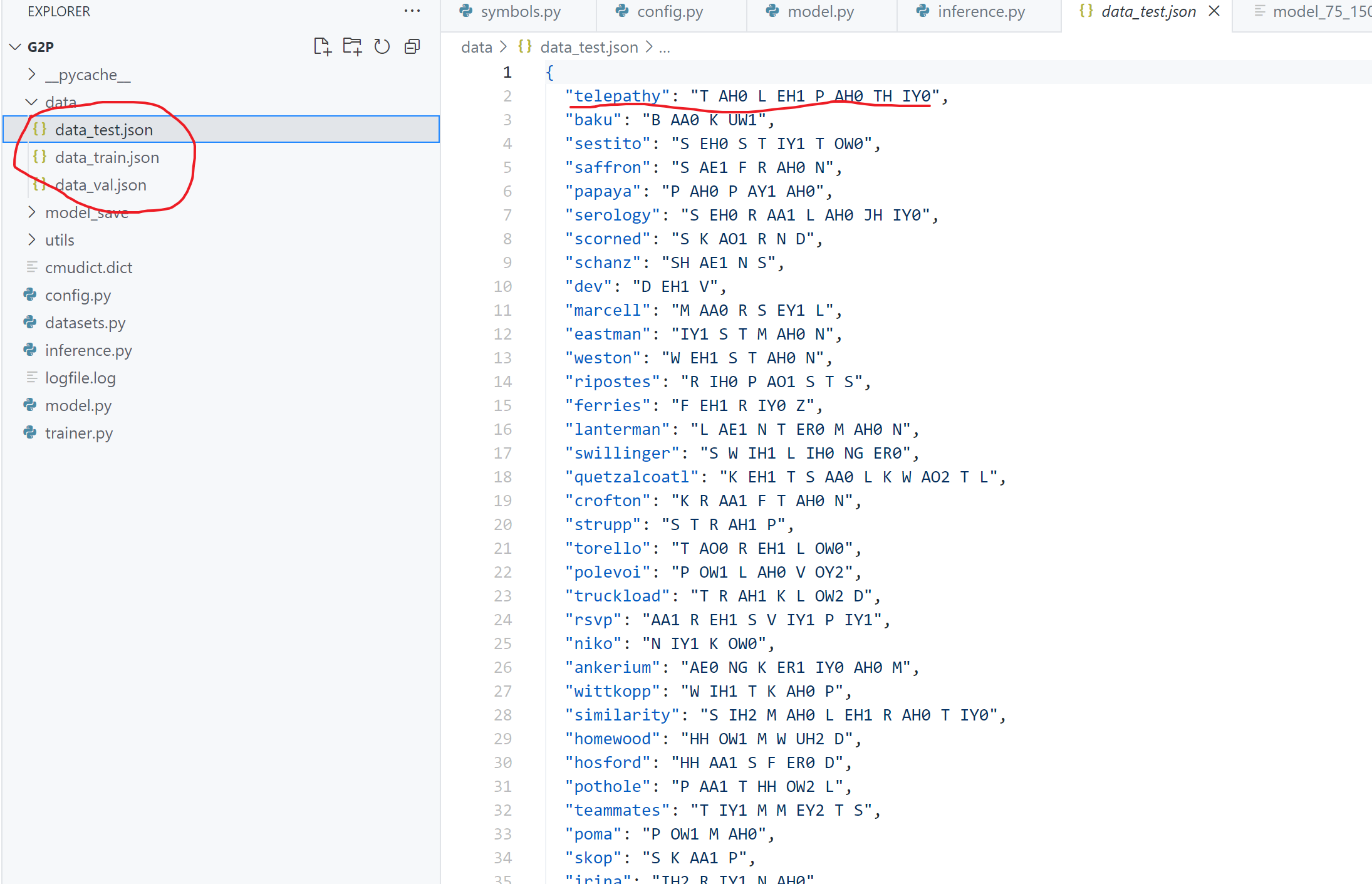
接着对数据进行预处理,将数据集按7:2:1 进行划分,划分后得到三个json 文件(如下图所示),同时我们预处理后的数据样式也如图中红线所示,一个单词对应一个发音音素。
数据预处理代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 ''' 数据预处理 ''' import jsonimport numpy as npdef generate_json (dataset: list , filename: str ): key = [] value = [] for data in dataset: idx = data.find(" " ) word = data[:idx] phenome = data[idx+1 :] if not word.isalpha() or '#' in phenome: continue key.append(word) value.append(phenome) json_data = dict (zip (key, value)) with open (f"data_{filename} .json" , 'w' ) as f: json.dump(json_data, f, indent=2 ) return json_data trainset_ratio = 0.7 val_ratio = 0.2 test_ratio = 0.1 f = open ("cmudict.dict" ,encoding="utf-8" ) dataset = f.read().splitlines() np.random.shuffle(dataset) n_items = len (dataset) trainset_num = int (trainset_ratio*n_items) valset_num = int (val_ratio*n_items) testset_num = n_items - trainset_num - valset_num train_data = dataset[:trainset_num] valset_data = dataset[trainset_num:trainset_num+valset_num] test_data = dataset[trainset_num+valset_num:] train_set = generate_json(train_data,'train' ) val_set = generate_json(valset_data,'val' ) test_set = generate_json(test_data,'test' ) print (len (train_set),len (val_set),len (test_set))
建议先看看上一篇文章明白Transformer的原理以及每个模块干嘛,否则会不理解代码实现
本次G2P 项目属于NLP 领域,因此我打算选用Transformer 作为本次项目的模型。接下来开始对Transformer 的代码进行具体实现。
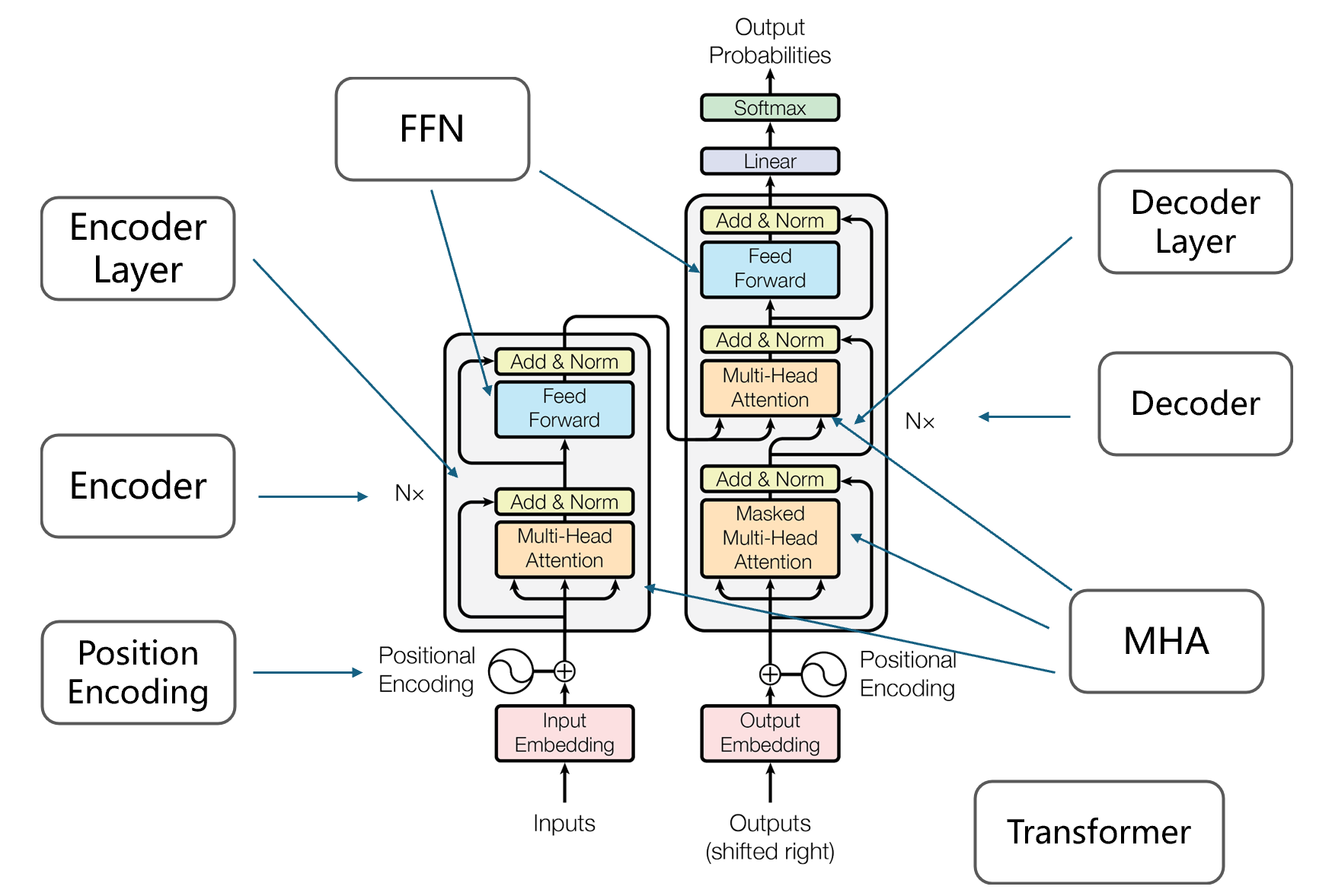
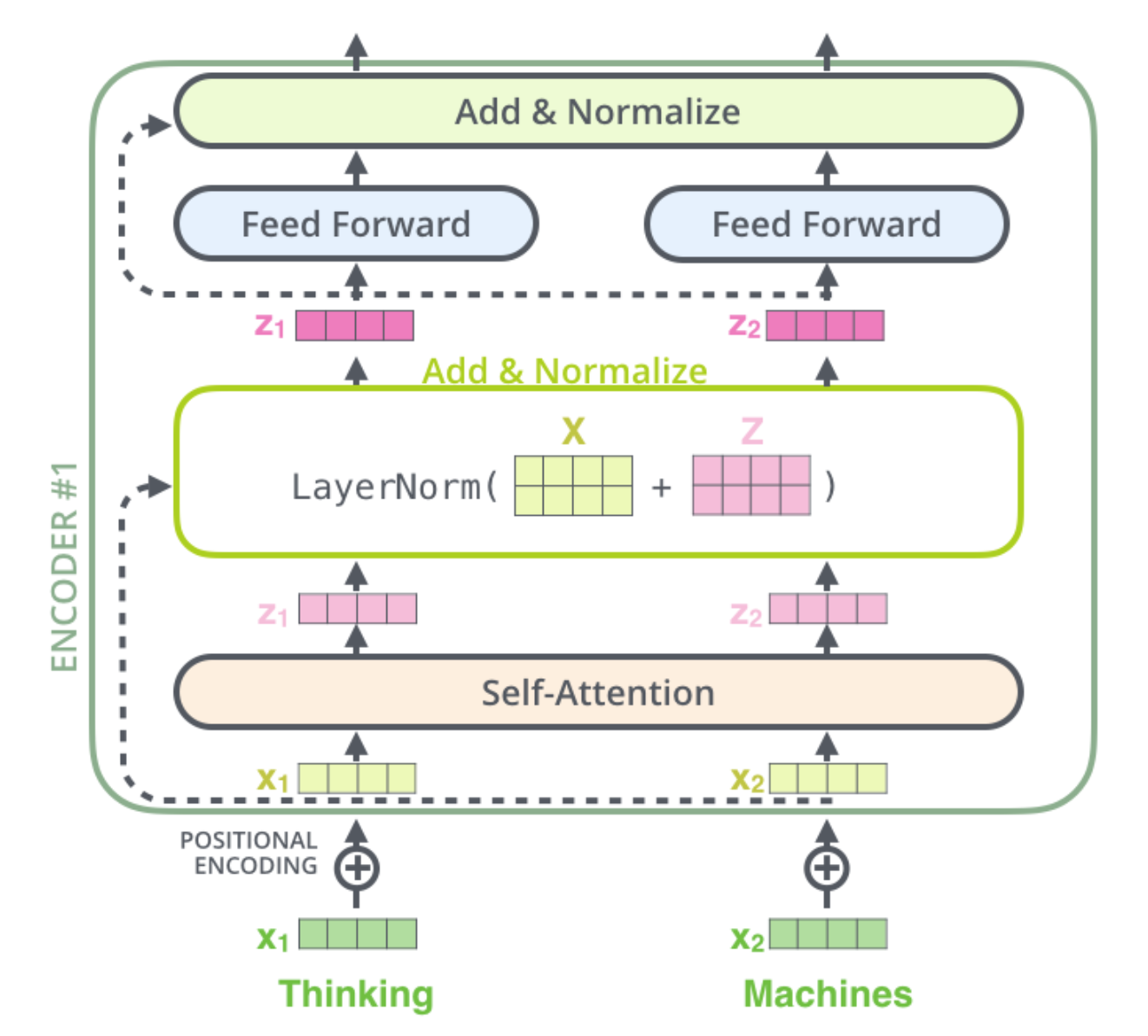
对于模型的实现,我们首先会分为8个类,如上图所示:
Transformer 类是对最后整体进行封装MHA 是多头注意力类FFN 是前向反馈网络类Positional Encoding 是位置编码类Encoder 是指N 个Encoder Layer 的堆叠,同理Decoder 是对多个Decoder Layer 的堆叠
Positional Encoding
为了使模型能够利用序列中的顺序信息,还需要注入一些关于tokens在序列中相对或绝对位置 的信息。为此,论文在编码器和解码器堆栈底部 的输入嵌入中加入了位置编码。位置编码的维度与嵌入向量相同即 d m o d e l d_{model} d m o d e l
P E ( p o s , 2 i ) = s i n ( p o s / 10000 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 2 i / d m o d e l ) PE(pos,2i)=sin(pos/10000^{2i/d_{model}})\\
PE(pos,2i+1)=cos(pos/1000^{2i/d_{model}})
PE ( p os , 2 i ) = s in ( p os /1000 0 2 i / d m o d e l ) PE ( p os , 2 i + 1 ) = cos ( p os /100 0 2 i / d m o d e l )
具体代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class PositionalEncoding (nn.Module): ''' PositionalEncoding 不带参数更新 PositionalEmbedding 带有参数更新 ''' def __init__ (self, d_model, max_len = 10000 ): super ().__init__() pe = torch.zeros(1 , max_len, d_model) position = torch.arange(0 , max_len).unsqueeze(1 ) div_term = torch.exp(torch.arange(0 , d_model, 2 ).float ()*(-math.log(10000.0 ))/d_model) pe[0 ,:,0 ::2 ] = torch.sin(position * div_term) pe[0 ,:,1 ::2 ] = torch.cos(position * div_term) self .register_buffer("pe" , pe) def forward (self, x ): x = x + self .pe[:,0 :x.size(1 ):,:] return x
Multi Head Attention
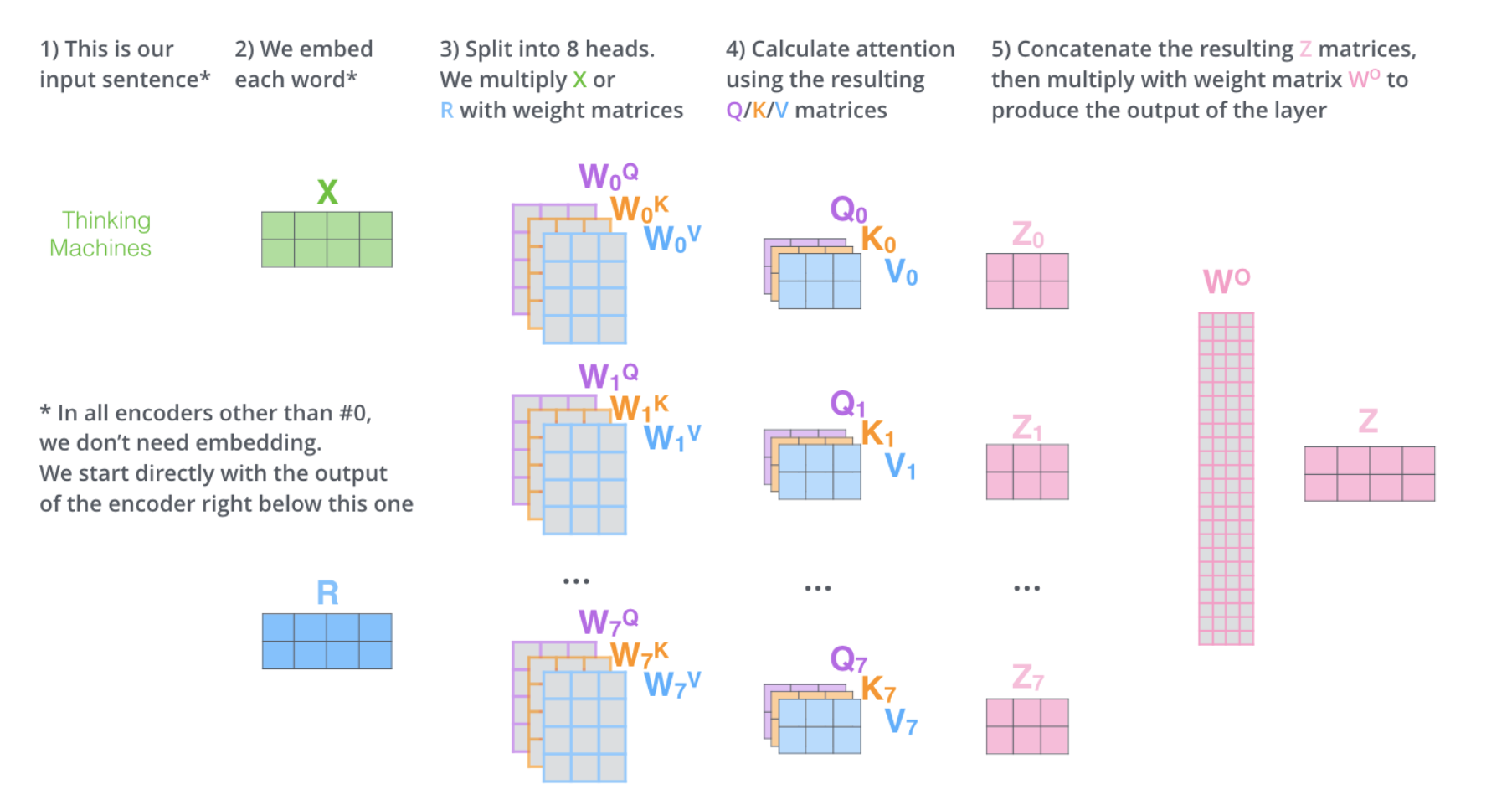
接着多头注意力机制实现,首先我们将输入通过一个Linear层转化成 Q,K,V,接着将 每个Q,K,V分成8个头(论文中是8个,看具体情况自己定义),接着进行注意力计算,最终在进行拼接返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class MultiHeadAttentionLayer (nn.Module): def __init__ (self, hid_dim, nhead ): super ().__init__() self .hid_dim = hid_dim self .nhead = nhead assert not self .hid_dim % self .nhead self .head_dim = self .hid_dim // self .nhead self .fc_q = nn.Linear(hid_dim, hid_dim) self .fc_k = nn.Linear(hid_dim, hid_dim) self .fc_v = nn.Linear(hid_dim, hid_dim) self .fc_o = nn.Linear(hid_dim, hid_dim) self .register_buffer('scale' , torch.sqrt(torch.tensor(hid_dim).float ())) def forward (self, query, key, value, inputs_mask = None ): N = query.size(0 ) Q = self .fc_q(query) K = self .fc_k(key) V = self .fc_v(value) Q = Q.view(N, -1 , self .nhead, self .head_dim).permute(0 , 2 , 1 , 3 ) K = K.view(N, -1 , self .nhead, self .head_dim).permute(0 , 2 , 1 , 3 ) V = V.view(N, -1 , self .nhead, self .head_dim).permute(0 , 2 , 1 , 3 ) energy = torch.matmul(Q, K.permute(0 , 1 , 3 , 2 )) / self .scale if inputs_mask is not None : energy = torch.masked_fill(energy, inputs_mask == 0 , -1.e10 ) attention = F.softmax(energy, dim = -1 ) out = torch.matmul(attention, V) out = out.permute(0 , 2 , 1 , 3 ).contiguous() out = out.view(N, -1 , self .hid_dim) out = self .fc_o(out) return out, attention
Feed Forward Layer
前向网络结构比较简单,两个线性层同时注意加上Dropout,因为线性层这里计算比较耗时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class PointWiseFeedForwardLayer(nn.Module): def __init__(self, hid_dim, pff_dim, pff_drop_out): super().__init__() self.hid_dim = hid_dim self.pff_dim = pff_dim self.pff_drop_out = pff_drop_out self.fc1 = nn.Linear(self.hid_dim, self.pff_dim) self.fc2 = nn.Linear(self.pff_dim, self.hid_dim) self.dropout = nn.Dropout(self.pff_drop_out) def forward(self, inputs): inputs = self.dropout(F.relu(self.fc1(inputs))) out = self.fc2(inputs) return out
Encoder Layer
首先一个Encoder Layer 的结构如下图所示:
代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class EncoderLayer (nn.Module): def __init__ (self, *args, **kwargs ): super ().__init__() self .self_att_layer_norm = nn.LayerNorm(HP.encoder_dim) self .pff_layer_norm = nn.LayerNorm(HP.encoder_dim) self .self_attn = MultiHeadAttentionLayer(HP.encoder_dim, HP.nhead) self .pff = PointWiseFeedForwardLayer(HP.encoder_dim,HP.encoder_feed_forward_dim, HP.ffn_drop_prob) self .drop = nn.Dropout(HP.encoder_drop_prob) def forward (self, inputs, inputs_mask ): _inputs, att_res = self .self_attn(inputs, inputs, inputs, inputs_mask) inputs = self .self_att_layer_norm(inputs+self .drop(_inputs)) _inputs = self .pff(inputs) inputs = self .pff_layer_norm(inputs+self .drop(_inputs)) return inputs
Encoder
编码器是多个Encoder Layer的堆叠,所以具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Encoder (nn.Module): def __init__ (self, ): super ().__init__() self .token_embedding = nn.Embedding(HP.grapheme_size, HP.encoder_dim) self .pe = PositionalEncoding(HP.encoder_dim, HP.encoder_max_input) self .layers = nn.ModuleList([EncoderLayer() for _ in range (HP.encoder_layer)]) self .drop = nn.Dropout(HP.encoder_drop_prob) self .register_buffer('scale' , torch.sqrt(torch.tensor(HP.encoder_dim).float ())) def forward (self, inputs, input_mask ): token_emb = self .token_embedding(inputs) inputs = self .pe(token_emb*self .scale) for idx, layer in enumerate (self .layers): inputs = layer(inputs, input_mask) return inputs
Decoder Layer
每一层解码器包含:
多头自注意力
Encoder-Decoder交叉注意力
FFN
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Decoder_layer (nn.Module): def __init__ (self, *args, **kwargs ): super ().__init__() self .mask_self_att = MultiHeadAttentionLayer(HP.decoder_dim, HP.nhead) self .mask_self_norm = nn.LayerNorm(HP.decoder_dim) self .mha = MultiHeadAttentionLayer(HP.decoder_dim, HP.nhead) self .mha_norm = nn.LayerNorm(HP.decoder_dim) self .pff = PointWiseFeedForwardLayer(HP.decoder_dim, HP.decoder_feed_forward_dim, HP.ffn_drop_prob) self .pff_norm = nn.LayerNorm(HP.decoder_dim) self .dropout = nn.Dropout(HP.decoder_drop_prob) def forward (self, trg, enc_src, trg_mask, src_mask ): _trg, _ = self .mask_self_att(trg, trg, trg, trg_mask) trg = self .mask_self_norm(trg + self .dropout(_trg)) _trg, attention = self .mha(trg, enc_src, enc_src, src_mask) trg = self .mha_norm(trg + self .dropout(_trg)) _trg = self .pff(trg) trg = self .pff_norm(trg + self .dropout(_trg)) return trg, attention
Decoder
同Encoder ,Decoder 是多个Decoder Layer 的堆叠
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Decoder (nn.Module): def __init__ (self, ): super ().__init__() self .token_embedding = nn.Embedding(HP.phoneme_size, HP.decoder_dim) self .pe = PositionalEncoding(HP.decoder_dim, HP.MAX_DECODE_STEP) self .layers = nn.ModuleList([Decoder_layer() for _ in range (HP.decoder_layer)]) self .fc_out = nn.Linear(HP.decoder_dim, HP.phoneme_size) self .drop = nn.Dropout(HP.decoder_drop_prob) self .register_buffer('scale' , torch.sqrt(torch.tensor(HP.decoder_dim).float ())) def forward (self, trg, enc_src, trg_mask, src_mask ): token_emb = self .token_embedding(trg) pos_emb = self .pe(token_emb*self .scale) trg = self .drop(pos_emb) for idx,layer in enumerate (self .layers): trg, attention = layer(trg, enc_src, trg_mask, src_mask) out = self .fc_out(trg) return out,attention
对上述所有模块进行封装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class Transformer (nn.Module): def __init__ (self ): super ().__init__() self .encoder = Encoder() self .decoder = Decoder() @staticmethod def create_src_mask (src ): mask = (src != HP.ENCODER_PAD_IDX).unsqueeze(1 ).unsqueeze(2 ).to(HP.device) return mask @staticmethod def cretea_trg_mask (trg ): trg_len = trg.size(1 ) pad_mask = (trg != HP.DECODER_PAD_IDX).unsqueeze(1 ).unsqueeze(2 ).to(HP.device) sub_mask = torch.tril(torch.ones((trg_len, trg_len),dtype = torch.uint8)).bool () trg_mask = pad_mask & sub_mask return trg_mask def forward (self, src, trg ): src_mask = self .create_src_mask(src) trg_mask = self .cretea_trg_mask(trg) enc_src = self .encoder(src, src_mask) output, attention = self .decoder(trg, enc_src, trg_mask, src_mask) print (output.shape) return output, attention def infer (self, x ): batch_size = x.size(0 ) src_mask = self .create_src_mask(x) enc_src = self .encoder(x, src_mask) trg = torch.zeros(size=(batch_size, 1 )).fill_(HP.DECODER_SOS_IDX).long().to(HP.device) decoder_step = 0 while True : if decoder_step == HP.MAX_DECODE_STEP: print ("Warning: Reached Max Decoder step" ) break trg_mask = self .cretea_trg_mask(trg) output, attention = self .decoder(trg, enc_src, trg_mask, src_mask) pred_token = output.argmax(-1 )[:,-1 ] trg = torch.cat((trg, pred_token.unsqueeze(0 )),dim=-1 ) if pred_token == HP.DECODER_EOS_IDX: print ("decoder done" ) break decoder_step+=1 return trg[:,1 :],attention
训练
具体训练脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 import osimport torchimport torch.nn as nnimport numpy as npimport loggingfrom model import Transformerfrom config import HPfrom datasets import G2pdataset,collate_fnfrom argparse import ArgumentParserfrom torch.utils.data import DataLoaderdef evaluate (model_, devloader, crit ): model_.eval () sum_loss = 0 with torch.no_grad(): for batch in devloader: word_idxs, word_len, phoneme_idxs, phoneme_len = batch output, attention = model_(word_idxs.to(HP.device), phoneme_idxs[:,:-1 ].to(HP.device)) out = output.view(-1 , output.size(-1 )) trg = phoneme_idxs[:,1 :] trg = trg.contiguous().view(-1 ) loss = crit(out.to(HP.device), trg.to(HP.device)) sum_loss += loss.item() model_.train() return sum_loss/len (devloader) def save_checkpoint (model_, epoch_, optm, checkpointpath ): save_dict = { 'epoch' : epoch_, 'model_state_dict' : model_.state_dict(), 'optimizer_state_dict' : optm.state_dict() } torch.save(save_dict, checkpointpath) def train (): logging.basicConfig( level=logging.DEBUG, format ="%(asctime)s - %(levelname)s - %(message)s" , filename="logfile.log" , filemode="a" ) parser = ArgumentParser(description="model training" ) parser.add_argument("--c" , default=None , type =str , help ="training from scratch or resume training" ) args = parser.parse_args() model = Transformer() model.to(HP.device) criterion = nn.CrossEntropyLoss(ignore_index=HP.DECODER_PAD_IDX) opt = torch.optim.Adam(model.parameters(), lr =HP.init_lr) trainset = G2pdataset(HP.train_dataset_path) train_loader = DataLoader(trainset, batch_size=HP.bs, shuffle=True , drop_last=True , collate_fn=collate_fn) devset = G2pdataset(HP.val_dataset_path) dev_loader = DataLoader(devset, batch_size=HP.bs, shuffle=True , drop_last=False , collate_fn=collate_fn) start_epoch, step = 0 ,0 if args.c: checkpoint = torch.load(args.c) model.load_state_dict(checkpoint['model_state_dict' ]) opt.load_state_dict(checkpoint['optimizer_state_dict' ]) start_epoch = checkpoint['epoch' ] print ("resume from %s." % args.c) else : print ("traing from scratch!" ) model.train() for epoch in range (start_epoch, HP.epochs): print ('Start Epoch:%d, Steps:%d' %(epoch, len (train_loader))) for batch in train_loader: word_idxs, word_len, phoneme_idxs, phoneme_len = batch opt.zero_grad() output, attention = model(word_idxs.to(HP.device), phoneme_idxs[:,:-1 ].to(HP.device)) out = output.view(-1 , output.size(-1 )) trg = phoneme_idxs[:,1 :] trg = trg.contiguous().view(-1 ) loss = criterion(out.to(HP.device), trg.to(HP.device)) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), HP.gard_clip_thresh) opt.step() if not step % HP.verbose_step: eval_loss = evaluate(model, dev_loader, criterion) if not step % HP.save_step: model_path = 'model_%d_%d.pth' % (epoch, step) save_checkpoint(model, epoch, opt, os.path.join('model_save' , model_path)) step +=1 logging.info("Epoch[%d/%d], step:%d, Train loss:%.5f, Dev loss:%.5f" %(epoch,HP.epochs, step,loss.item(),eval_loss)) if __name__ == "__main__" : train()
我在一张A800显卡上训练了50分钟,总共100个Epoch,batch size大小为4096.
推理
基于上述训练的模型进行推理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from model import Transformerimport torchfrom config import HPfrom utils.symbols import word2id, id2phonemeimport matplotlib.pyplot as pltimport osimport numpy as npmodel = Transformer() checkpoint = torch.load(r"model_save/model_75_1500.pth" ,map_location="cpu" ) model.load_state_dict(checkpoint['model_state_dict' ]) while 1 : word = input ("Input: " ).strip() wordids = word2id(word.lower()) wordids = [HP.ENCODER_SOS_IDX] +wordids +[HP.ENCODER_EOS_IDX] wordids = torch.tensor(wordids).unsqueeze(0 ) phonemes, attention = model.infer(wordids) phonemes_list = phonemes.squeeze().cpu().numpy().tolist() phoneme_seq = id2phoneme(phonemes_list) print (phoneme_seq) print (attention.size()) word_tokens = ['<s>' ] + list (word.lower()) +['</s>' ] phoneme_tokens = phoneme_seq.split(" " ) atten_map_weight = torch.sum (attention.squeeze(),dim=0 ) attn_matrix = atten_map_weight.transpose(0 ,1 ).detach().cpu().numpy() fig,ax = plt.subplots() im = ax.imshow(attn_matrix) ax.set_xticks(np.arange(len (phoneme_tokens))) ax.set_yticks(np.arange(len (word_tokens))) ax.set_xticklabels(phoneme_tokens) ax.set_yticklabels(word_tokens) plt.setp(ax.get_xticklabels()) ax.set_title("word-phoneme Attention Map" ) fig.tight_layout() plt.show()
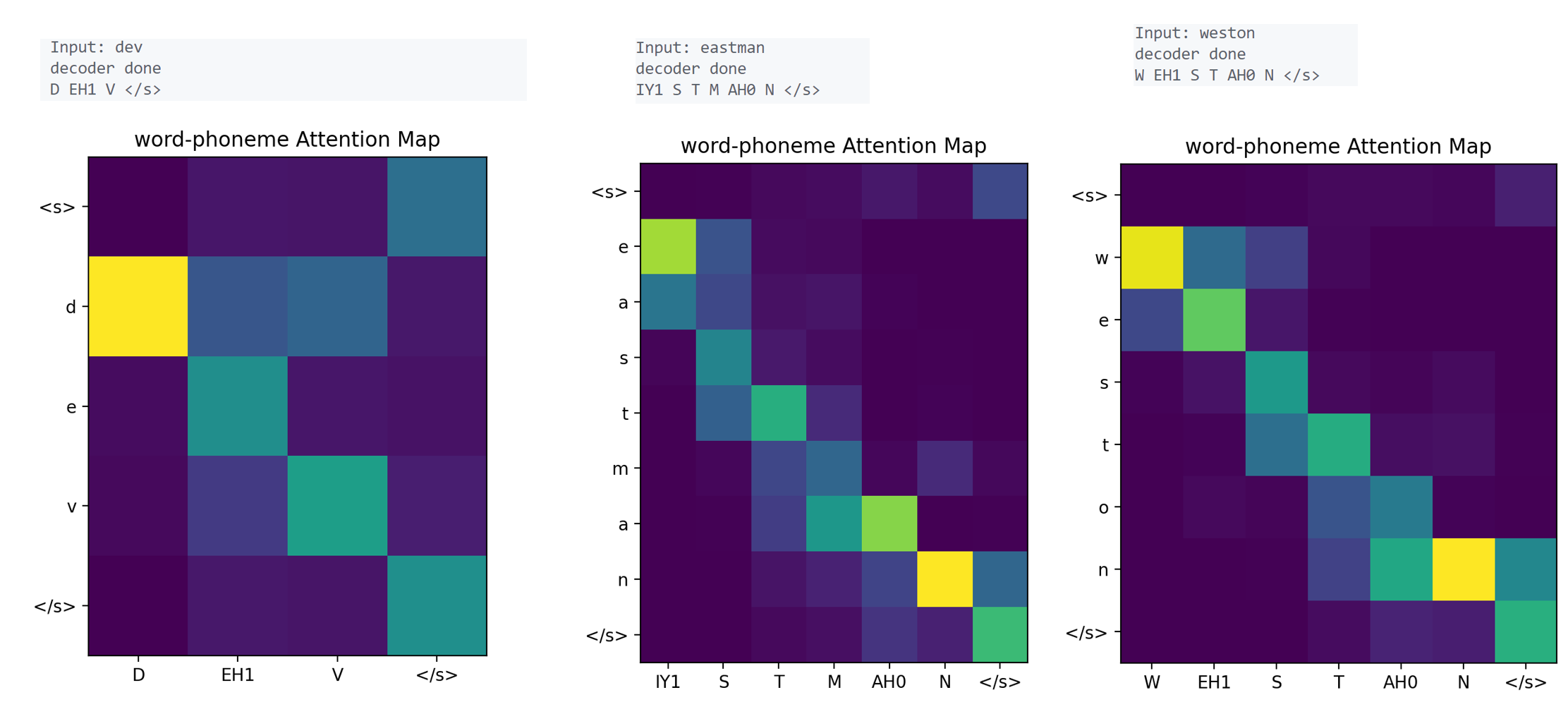
推理示例:
从测试集随便找三个单词如图,分别是“dev”,“eastman”,“weston”
然后执行推理脚本:
可以发现在测试集 上全部解码正确,训练时并未用到测试集,说明模型训练的效果很不错。