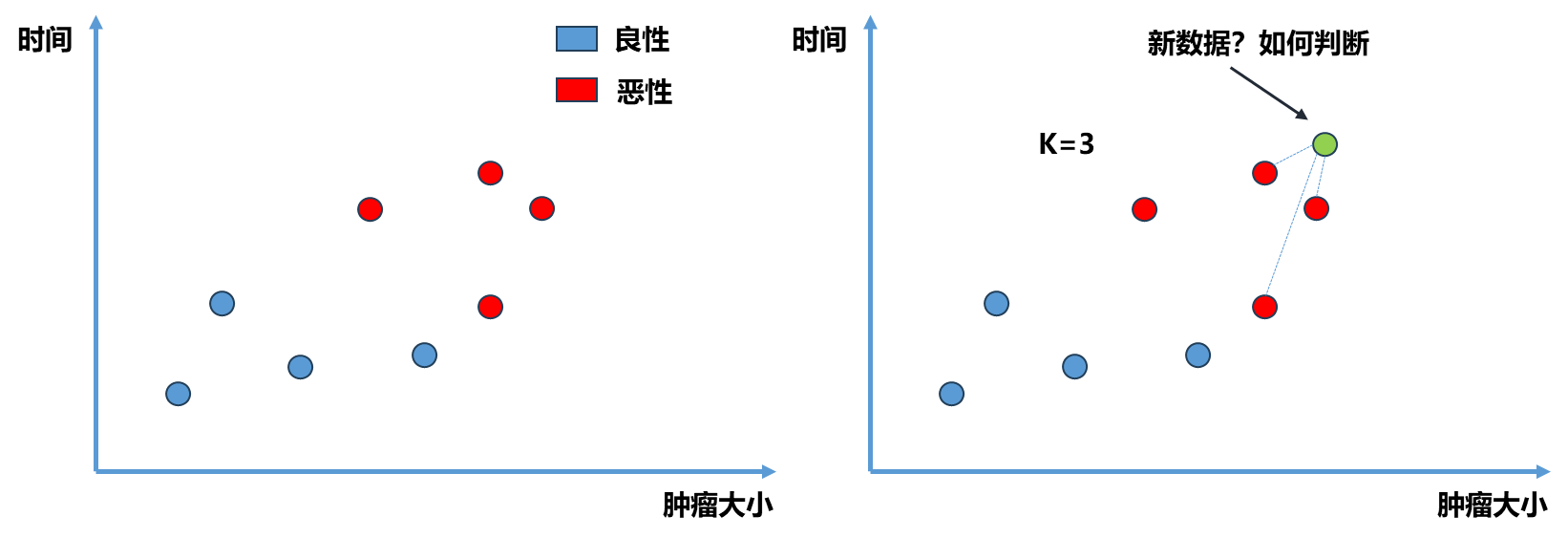
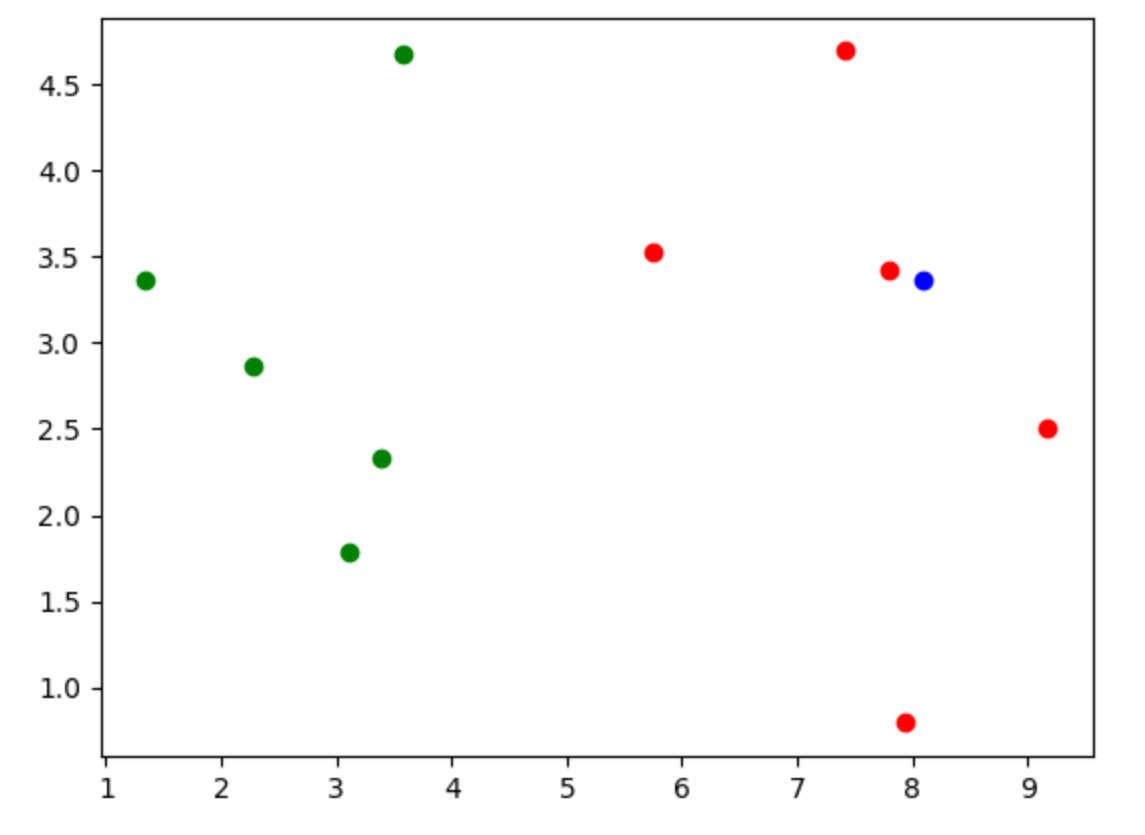
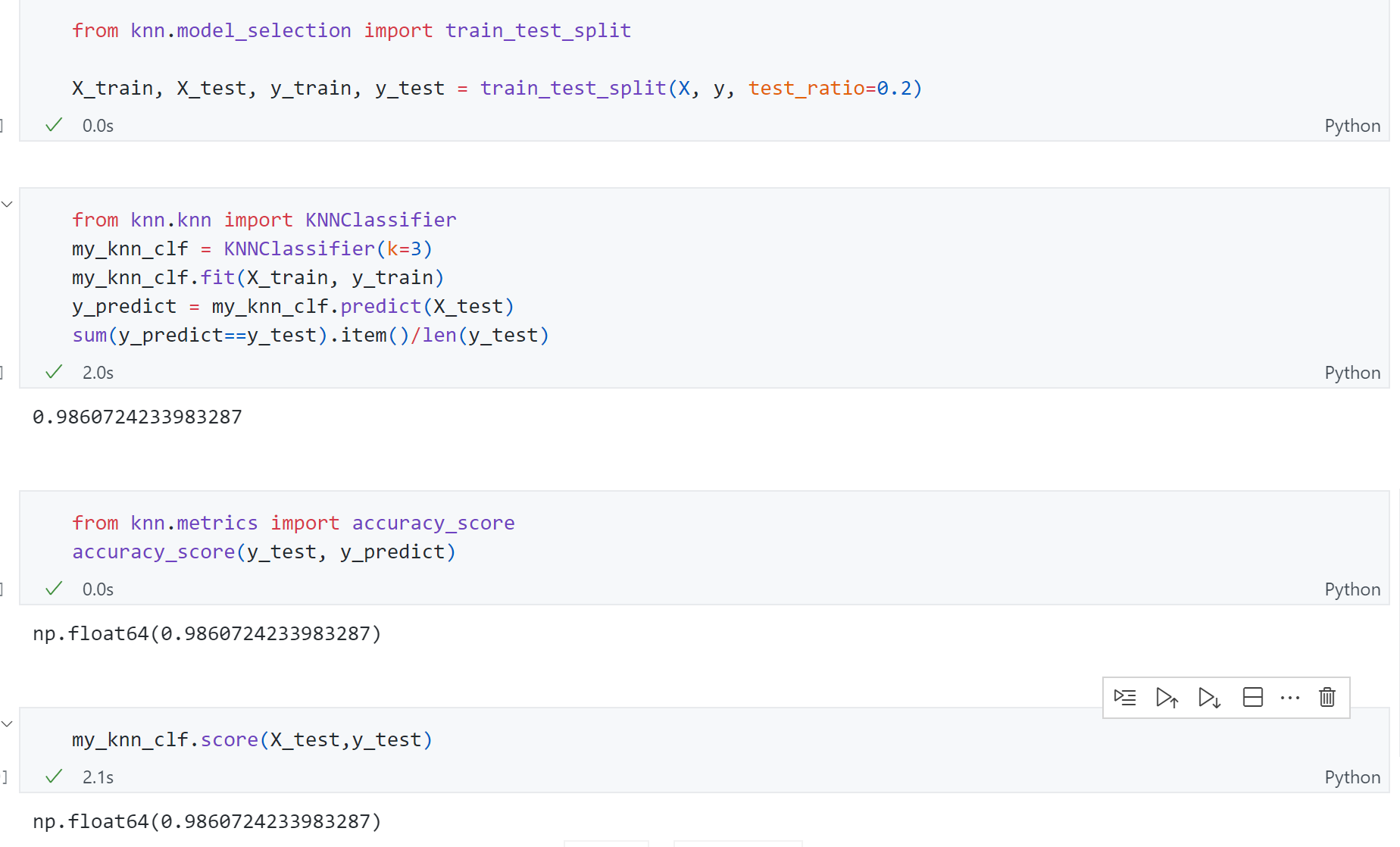
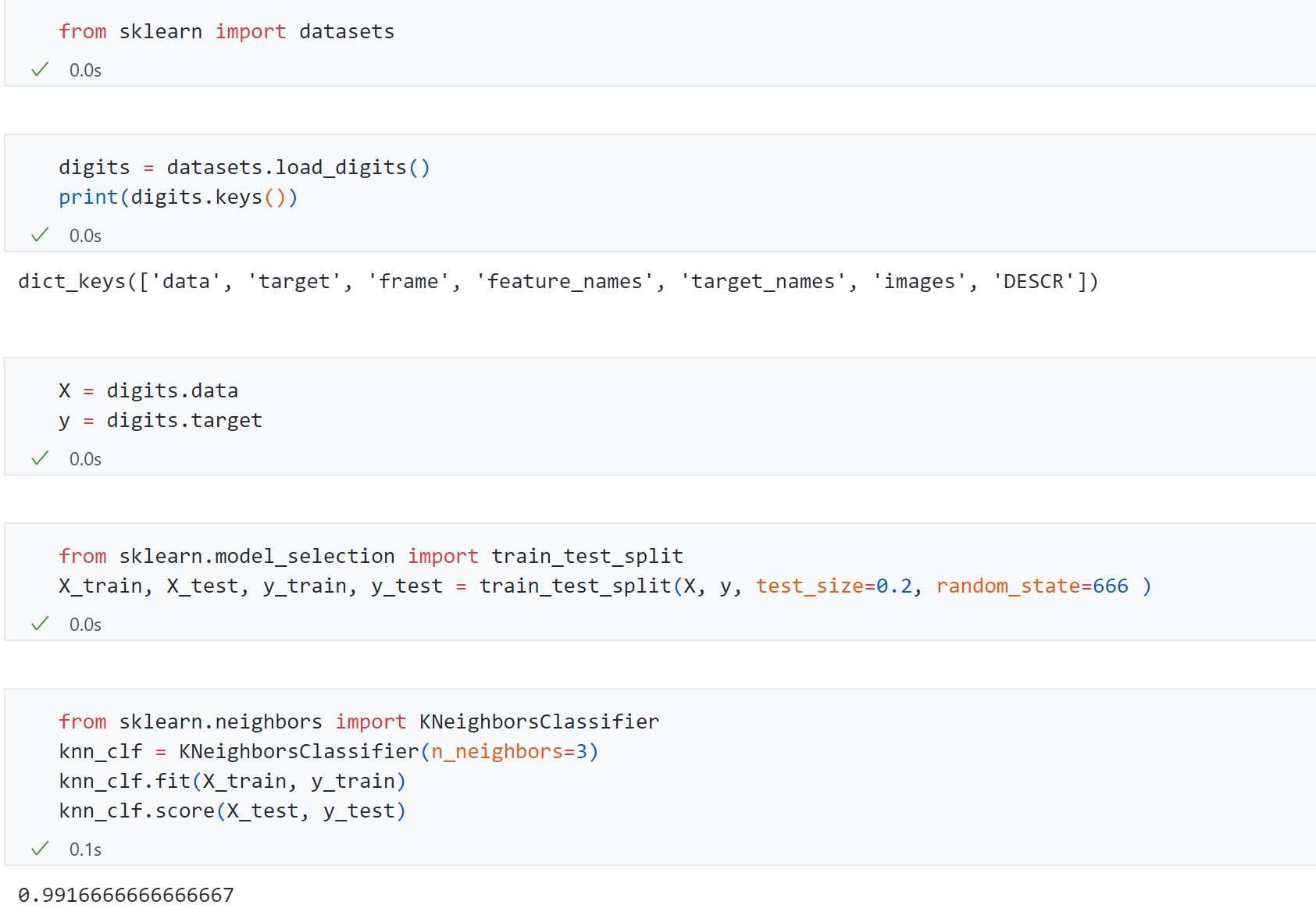
import numpy as np import matplotlib.pyplot as plt from math import sqrt
from collections import Counter
classKNNClassifier(): def__init__(self, k): assert k>=1,"k must be valid" self.k = k self._X_train = None self._y_train = None deffit(self, X_train, y_train): assert X_train.shape[0] == y_train.shape[0],\ "the size of X_train must be equal to the size of y_train" assertself.k <= X_train.shape[0],\ "the size of k must be at least k"
self._X_train = X_train self._y_train = y_train returnself defpredict(self, X_precit): assertself._X_train isnotNoneandself._y_train isnotNone,\ "must fit before predict" assert X_precit.shape[1]==self._X_train.shape[1],\ "the feature number of X_predict must be equal to X_train"
y_predcit = [self._predict(x) for x in X_precit] return np.array(y_predcit) def_predict(self, x): assert x.shape[0]==self._X_train.shape[1],\ "the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train-x)**2)) for x_train inself._X_train] nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]] votes = Counter(topK_y)
deftrain_test_split(X, y, test_ratio=0.2, seed=None): assert X.shape[0] == y.shape[0],\ "the size of X must be equal to the size of y" assert0.0 <= test_ratio <= 1.0 ,\ "test_ration must be valid"
defaccuracy_score(y_true, y_predcit): assert y_true.shape[0] == y_predcit.shape[0], \ "the size of y_true must be equal to the size of y_predict" returnsum(y_true==y_predcit)/len(y_true)
import numpy as np import matplotlib.pyplot as plt from math import sqrt from .metrics import accuracy_score
from collections import Counter
classKNNClassifier(): def__init__(self, k): assert k>=1,"k must be valid" self.k = k self._X_train = None self._y_train = None deffit(self, X_train, y_train): assert X_train.shape[0] == y_train.shape[0],\ "the size of X_train must be equal to the size of y_train" assertself.k <= X_train.shape[0],\ "the size of k must be at least k"
self._X_train = X_train self._y_train = y_train returnself defpredict(self, X_precit): assertself._X_train isnotNoneandself._y_train isnotNone,\ "must fit before predict" assert X_precit.shape[1]==self._X_train.shape[1],\ "the feature number of X_predict must be equal to X_train"
y_predcit = [self._predict(x) for x in X_precit] return np.array(y_predcit) def_predict(self, x): assert x.shape[0]==self._X_train.shape[1],\ "the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train-x)**2)) for x_train inself._X_train] nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]] votes = Counter(topK_y)
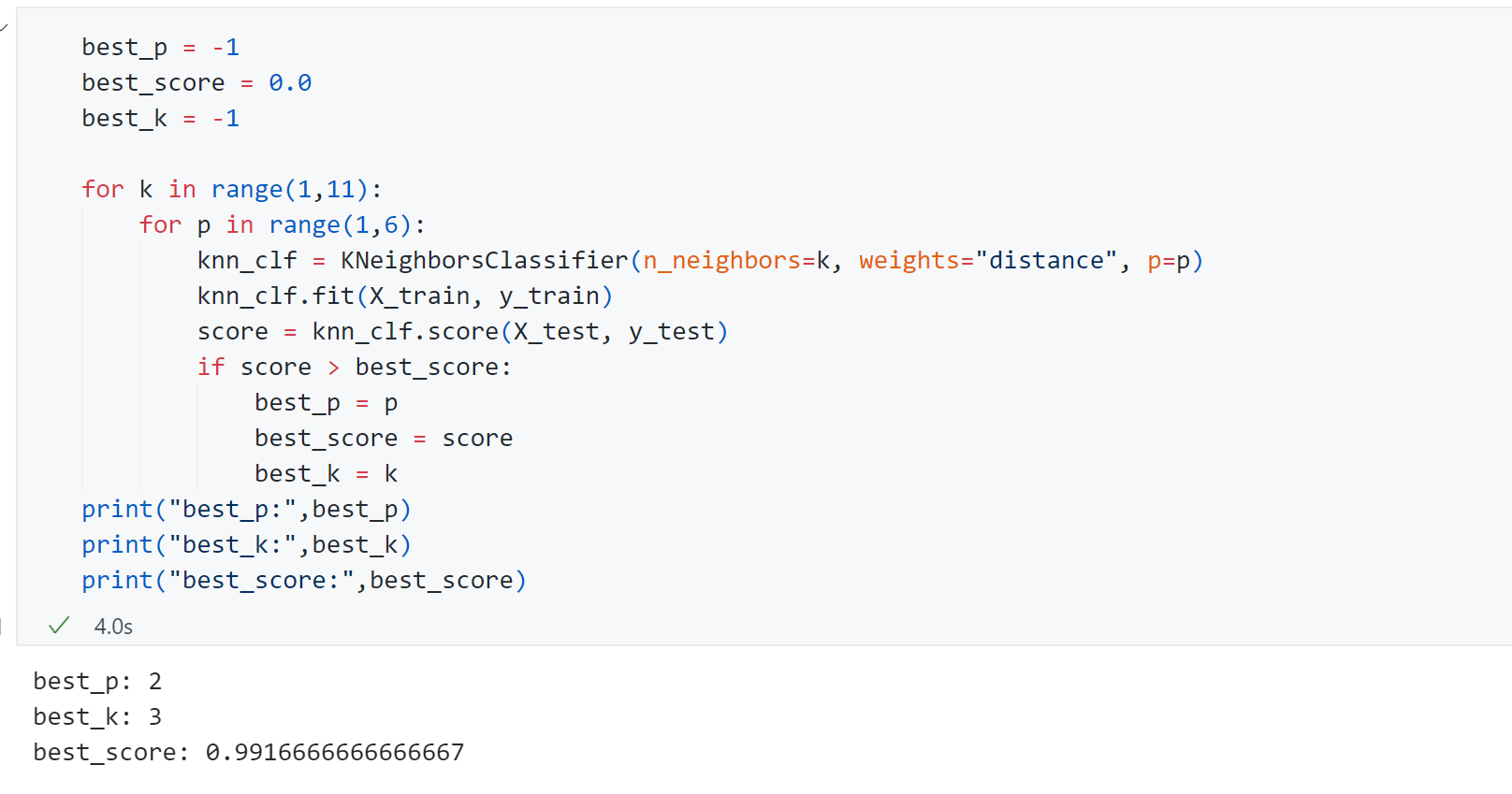
param_grid = [ { 'weights':['uniform'], 'n_neighbors':[i for i inrange(1,11)] }, { 'weights':['distance'], 'n_neighbors':[i for i inrange(1,11)], 'p':[i for i inrange(1,6)] } ]