Linear Regression
线性回归 主要用于解决回归 问题,而上次介绍的KNN 主要用于分类 问题。线性回归同样思想简单并且实现容易(与其背后非常强的数学性质相关),虽然线性回归非常简单,但它是许多强大的非线性模型的基础 。无论是多项式回归、逻辑回归甚至是SVM ,从某种程度上都可以理解是线性回归的一种拓展 。同时线性回归得到的结果具有很好的可解释性。
什么是线性回归算法?
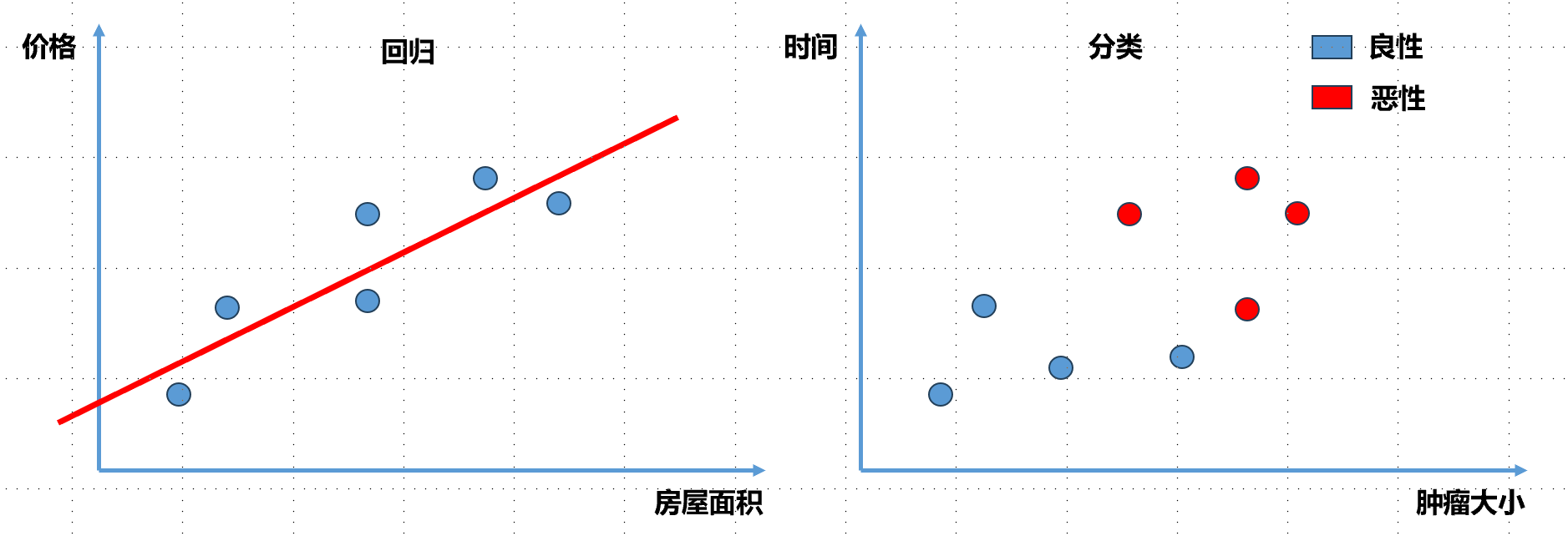
看下面图中每一个点表示一个数据,每个数据点有自己的房屋面积以及相应的价格。线性回归算法认为房屋面积和价格之间成一定的线性关系,随着房屋面积增大,价格也会线性增长。在这种假设下,我们在想能不能找到一条直线,最大程度的拟合样本特征和样本输出标记之间的关系
同时注意上一节的分类问题中数据点横轴肿瘤大小 和纵轴时间都是样本特征 ,每一个点有两个样本特征,样本输出标记 是由红色蓝色 表示的。在左图回归的例子中,横轴房屋面积 就是样本特征 ,而纵轴价格 就是样本的输出标记 。这主要是因为回归问题中真正要预测的是一个具体的数值,这个具体的数值是在一个连续的空间中而不是可以简单的用不同颜色代表不同类别 。所以需要占用一个坐标轴位置。
上面例子中样本特征只有一个 ,被称为简单线性回归
对于简单线性回归,假设我们找到了最佳拟合的直线方程:
y = a x + b y=ax+b
y = a x + b
对于每一个样本点x ( i ) x^{(i)} x ( i )
y ^ ( i ) = a x ( i ) + b \hat{y}^{(i)}=ax^{(i)}+b
y ^ ( i ) = a x ( i ) + b
对于每一个样本点x ( i ) x^{(i)} x ( i ) y ( i ) y^{(i)} y ( i ) y ( i ) y^{(i)} y ( i ) y ^ ( i ) \hat{y}^{(i)} y ^ ( i )
表达y ( i ) y^{(i)} y ( i ) y ^ ( i ) \hat{y}^{(i)} y ^ ( i ) y ( i ) − y ^ ( i ) y^{(i)}-\hat{y}^{(i)} y ( i ) − y ^ ( i )
∣ y ( i ) − y ^ ( i ) ∣ |y^{(i)}-\hat{y}^{(i)}|
∣ y ( i ) − y ^ ( i ) ∣
使用绝对值表示差异没有问题,但是后续用来计算a , b a,b a , b
( y ( i ) − y ^ ( i ) ) 2 (y^{(i)}-\hat{y}^{(i)})^2
( y ( i ) − y ^ ( i ) ) 2
平方同样抵消了正负号,同时y = x 2 y=x^2 y = x 2
∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 \sum^{m}_{i=1}(y^{(i)}-\hat{y}^{(i)})^2
i = 1 ∑ m ( y ( i ) − y ^ ( i ) ) 2
因此目标:
使 ∑ i = 1 m ( y ( i ) − y ^ ( i ) ) 2 尽可能小 代入 y ^ ( i ) = a x ( i ) + b 目标找到 a , b 使得 ∑ i = 1 m ( y ( i ) − a x ( i ) − b ) 2 尽可能小 使\sum^{m}_{i=1}(y^{(i)}-\hat{y}^{(i)})^2尽可能小\\
代入\hat{y}^{(i)}=ax^{(i)}+b\\
目标找到a,b使得\sum^{m}_{i=1}(y^{(i)}-ax^{(i)}-b)^2尽可能小
使 i = 1 ∑ m ( y ( i ) − y ^ ( i ) ) 2 尽可能小 代入 y ^ ( i ) = a x ( i ) + b 目标找到 a , b 使得 i = 1 ∑ m ( y ( i ) − a x ( i ) − b ) 2 尽可能小
这也是一类机器学习算法的基本思路:找到一些参数值,使得 目标function 尽可能大或小
所谓建模的过程其实就是找到一个模型最大程度拟合我们的数据,在线性回归算法中这个模型就是一个方程,最大拟合数据本质就找到这样一个函数,这里叫损失函数Loss function,度量出模型没有拟合出样本的这一部分,有些算法可能度量拟合的程度,这种情况下称做效用函数(utility function).
不管哪个函数,机器学习都是先分析问题确定问题的损失函数或者效用函数,通过最优化损失函数或效用函数,获得机器学习模型。
几乎所有参数学习的算法都是这个套路,区别在于模型不同建立的目标函数不同,优化方式也是不同的。正是因为机器学习算法大部分都是这个思路,有一个学科 最优化原理。
最小二乘法
上面将问题最终转化成一个最优化问题:
目标 : 找到 a , b 使得 ∑ i = 1 m ( y ( i ) − a x ( i ) − b ) 2 ⏟ J(a,b) 尽可能小 目标:找到a,b使得\sum_{i=1}^{m}\underbrace{(y^{(i)}-ax^{(i)}-b)^2}_{\text{J(a,b)}}尽可能小
目标 : 找到 a , b 使得 i = 1 ∑ m J(a,b) ( y ( i ) − a x ( i ) − b ) 2 尽可能小
将里面式子记为J ( a , b ) J(a,b) J ( a , b ) a , b a,b a , b
∂ J ( a , b ) ∂ b = ∑ i = 1 m 2 ( y ( i ) − a x ( i ) − b ) ( − 1 ) = 0 ∑ i = 1 m ( y ( i ) − a x ( i ) − b ) = 0 ∑ i = 1 m y ( i ) − a ∑ i = 1 m x ( i ) − ∑ i = 1 m b = 0 m b = ∑ i = 1 m y ( i ) − a ∑ i = 1 m x ( i ) b = y ˉ − a x ˉ ( 1 ) − − − − − − − − − − − − − − − − − − − − − − − − − − − − ∂ J ( a , b ) ∂ a = ∑ i = 1 m 2 ( y ( i ) − a x ( i ) − b ) ( − x ( i ) ) = 0 ∑ i = 1 m ( y ( i ) − a x ( i ) − b ) x ( i ) = 0 ∑ i = 1 m ( y ( i ) − a x ( i ) − y ˉ + a x ˉ ) x ( i ) = 0 代入 ( 1 ) 式 ∑ i = 1 m ( x ( i ) y ( i ) − a ( x ( i ) ) 2 − x ( i ) y ˉ + a x ˉ x ( i ) ) = 0 ∑ i = 1 m ( x ( i ) y ( i ) − x ( i ) y ˉ − a ( x ( i ) ) 2 + a x ˉ x ( i ) ) = 0 ∑ i = 1 m ( x ( i ) y ( i ) − x ( i ) y ˉ ) − a ∑ i = 1 m ( ( x ( i ) ) 2 − x ˉ x ( i ) ) = 0 a = ∑ i = 1 m ( x ( i ) y ( i ) − x ( i ) y ˉ ) ∑ i = 1 m ( ( x ( i ) ) 2 − x ˉ x ( i ) ) \frac{\partial J(a,b)}{\partial b}=\sum_{i=1}^{m}2(y^{(i)}-ax^{(i)}-b)(-1)=0\\
\sum_{i=1}^{m}(y^{(i)}-ax^{(i)}-b)=0\\
\sum_{i=1}^{m}y^{(i)}-a\sum_{i=1}^{m}x^{(i)}-\sum_{i=1}^{m}b=0\\
mb=\sum_{i=1}^{m}y^{(i)}-a\sum_{i=1}^{m}x^{(i)}\\
b=\bar{y}-a\bar{x} \quad\quad(1)\\
----------------------------\\
\frac{\partial J(a,b)}{\partial a}=\sum_{i=1}^{m}2(y^{(i)}-ax^{(i)}-b)(-x^{(i)})=0\\
\sum_{i=1}^{m}(y^{(i)}-ax^{(i)}-b)x^{(i)}=0\\
\sum_{i=1}^{m}(y^{(i)}-ax^{(i)}-\bar{y}+a\bar{x})x^{(i)}=0 \quad \quad代入(1)式\\
\sum_{i=1}^{m}(x^{(i)}y^{(i)}-a(x^{(i)})^2-x^{(i)}\bar{y}+a\bar{x}x^{(i)})=0 \\
\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\bar{y}-a(x^{(i)})^2+a\bar{x}x^{(i)})=0 \\
\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\bar{y})-a\sum_{i=1}^{m}((x^{(i)})^2-\bar{x}x^{(i)})=0 \\
a=\frac{\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\bar{y})}{\sum_{i=1}^{m}((x^{(i)})^2-\bar{x}x^{(i)})}\\
∂ b ∂ J ( a , b ) = i = 1 ∑ m 2 ( y ( i ) − a x ( i ) − b ) ( − 1 ) = 0 i = 1 ∑ m ( y ( i ) − a x ( i ) − b ) = 0 i = 1 ∑ m y ( i ) − a i = 1 ∑ m x ( i ) − i = 1 ∑ m b = 0 mb = i = 1 ∑ m y ( i ) − a i = 1 ∑ m x ( i ) b = y ˉ − a x ˉ ( 1 ) − − − − − − − − − − − − − − − − − − − − − − − − − − − − ∂ a ∂ J ( a , b ) = i = 1 ∑ m 2 ( y ( i ) − a x ( i ) − b ) ( − x ( i ) ) = 0 i = 1 ∑ m ( y ( i ) − a x ( i ) − b ) x ( i ) = 0 i = 1 ∑ m ( y ( i ) − a x ( i ) − y ˉ + a x ˉ ) x ( i ) = 0 代入 ( 1 ) 式 i = 1 ∑ m ( x ( i ) y ( i ) − a ( x ( i ) ) 2 − x ( i ) y ˉ + a x ˉ x ( i ) ) = 0 i = 1 ∑ m ( x ( i ) y ( i ) − x ( i ) y ˉ − a ( x ( i ) ) 2 + a x ˉ x ( i ) ) = 0 i = 1 ∑ m ( x ( i ) y ( i ) − x ( i ) y ˉ ) − a i = 1 ∑ m (( x ( i ) ) 2 − x ˉ x ( i ) ) = 0 a = ∑ i = 1 m (( x ( i ) ) 2 − x ˉ x ( i ) ) ∑ i = 1 m ( x ( i ) y ( i ) − x ( i ) y ˉ )
对a a a
∑ i = 1 m x ( i ) y ˉ = y ˉ ∑ i = 1 m x ( i ) = m y ˉ x ˉ = x ˉ ∑ i = 1 m y ( i ) = ∑ i = 1 m x ˉ y ( i ) = ∑ i = 1 m x ˉ y ˉ a = ∑ i = 1 m ( x ( i ) y ( i ) − x ( i ) y ˉ − x ˉ y ( i ) + x ˉ y ˉ ) ∑ i = 1 m ( ( x ( i ) ) 2 − x ˉ x ( i ) − x ˉ x ( i ) + x ˉ 2 ) a = ∑ i = 1 m ( x ( i ) − x ˉ ) ( y ( i ) − y ˉ ) ∑ i = 1 m ( x ( i ) − x ˉ ) 2 ( 2 ) \sum_{i=1}^{m}x^{(i)}\bar{y}=\bar{y}\sum_{i=1}^{m}x^{(i)}=m\bar{y}\bar{x}=\bar{x}\sum_{i=1}^{m}y^{(i)}=\sum_{i=1}^{m}\bar{x}y^{(i)}=\sum_{i=1}^{m}\bar{x}\bar{y}\\
a=\frac{\sum_{i=1}^{m}(x^{(i)}y^{(i)}-x^{(i)}\bar{y}-\bar{x}y^{(i)}+\bar{x}\bar{y})}{\sum_{i=1}^{m}((x^{(i)})^2-\bar{x}x^{(i)}-\bar{x}x^{(i)}+\bar{x}^2)}\\
a=\frac{\sum_{i=1}^{m}(x^{(i)}-\bar{x})(y^{(i)}-\bar{y})}{\sum_{i=1}^{m}(x^{(i)}-\bar{x})^2}\quad\quad(2)\\
i = 1 ∑ m x ( i ) y ˉ = y ˉ i = 1 ∑ m x ( i ) = m y ˉ x ˉ = x ˉ i = 1 ∑ m y ( i ) = i = 1 ∑ m x ˉ y ( i ) = i = 1 ∑ m x ˉ y ˉ a = ∑ i = 1 m (( x ( i ) ) 2 − x ˉ x ( i ) − x ˉ x ( i ) + x ˉ 2 ) ∑ i = 1 m ( x ( i ) y ( i ) − x ( i ) y ˉ − x ˉ y ( i ) + x ˉ y ˉ ) a = ∑ i = 1 m ( x ( i ) − x ˉ ) 2 ∑ i = 1 m ( x ( i ) − x ˉ ) ( y ( i ) − y ˉ ) ( 2 )
实现Simple Linear Regression
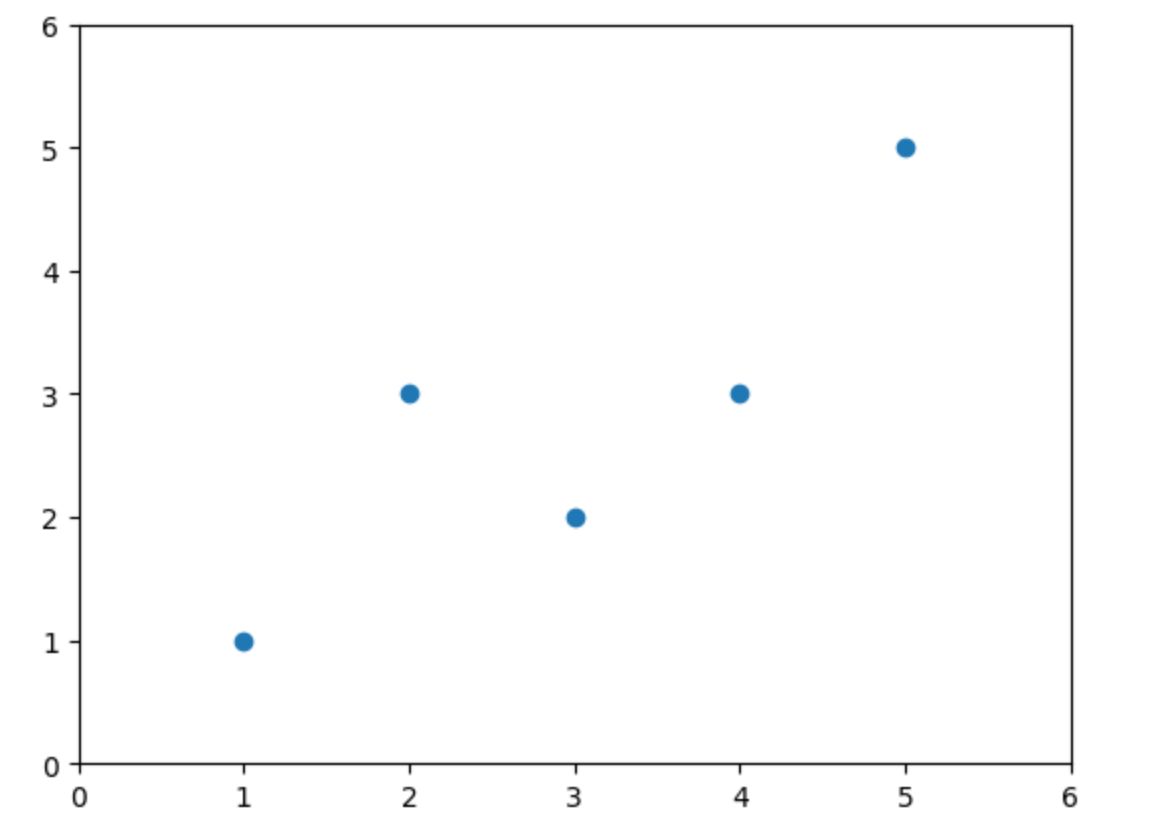
假如我们有如下数据点:
然后根据上面推出的式(1)和式(2)编程求解a , b a,b a , b
1 2 3 4 5 6 7 8 x_mean, y_mean = np.mean(x), np.mean(y) numerator = 0.0 denominator = 0.0 for x_i, y_i in zip (x,y): numerator += (x_i-x_mean)*(y_i-y_mean) denominator += (x_i-x_mean)**2 a = numerator/denominator b = y_mean - a*x_mean
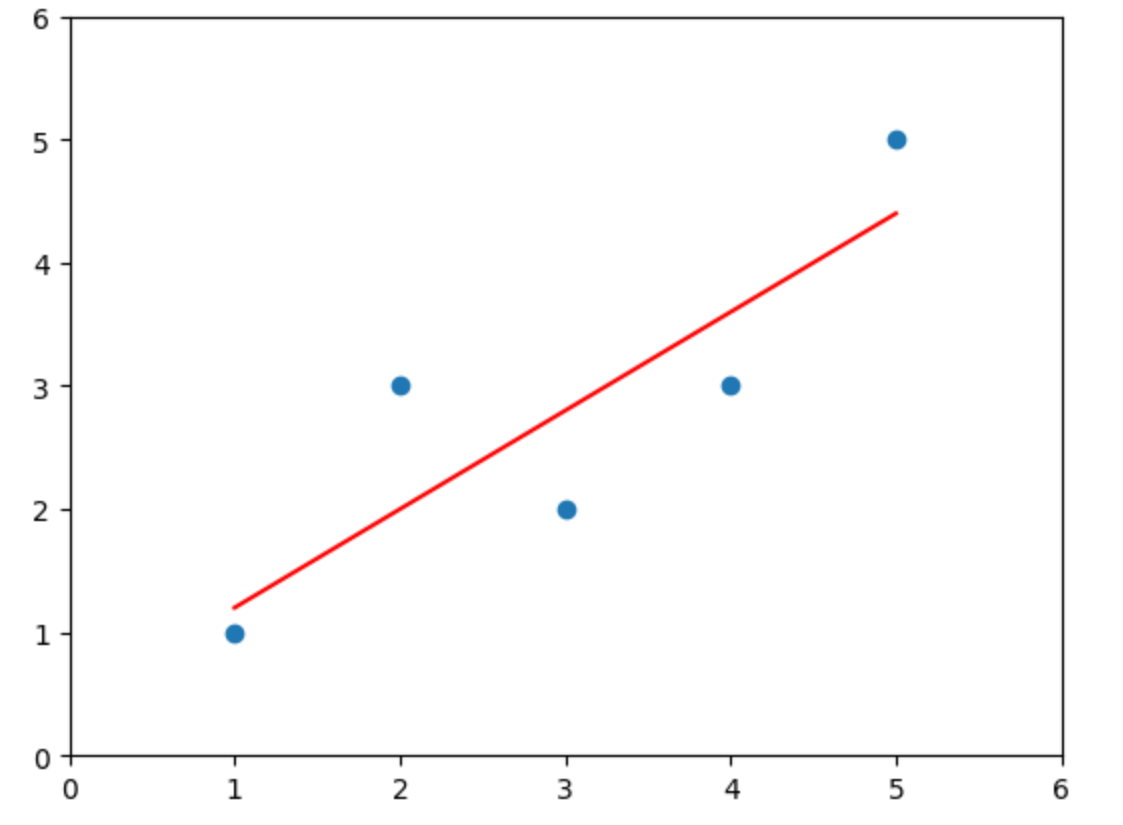
针对上述5个数据点我求的a , b a,b a , b 0.8和0.4 ,然后绘制到图中:
对于一个新来的数据点比如x=6 ,我们带入公式可得此时y = 0.8 ∗ 6 + 0.4 = 5.2 y=0.8*6+0.4=5.2 y = 0.8 ∗ 6 + 0.4 = 5.2
封装自己的算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import numpy as npclass SimpleLinearRegression1 : def __init__ (self ): self .a_ = None self .b_ = None def fit (self, x_train, y_train ): assert x_train.ndim==1 ,\ "Simple Linear Regression can only slove single feature training data" assert len (x_train) == len (y_train),\ "the size of x_trian must be equle to the size of y_train" x_mean, y_mean = np.mean(x_train), np.mean(y_train) numerator = 0.0 denominator = 0.0 for x_i, y_i in zip (x_train, y_train): numerator += (x_i-x_mean)*(y_i-y_mean) denominator += (x_i-x_mean)**2 self .a_ = numerator/denominator self .b_ = y_mean - self .a_*x_mean return self def predict (self, x_predict ): assert x_predict.ndim==1 ,\ "Simple Linear Regression can only slove single feature training data" assert self .a_ is not None and self .b_ is not None ,\ "must fit before predict" return np.array([self ._predict(x) for x in x_predict]) def _predcit (self, x_single ): return self .a_*x_single + self .b_ def __repr__ (self ): return "SimpleLinearRegression1()"
向量化
上面封装算法时采用for循环的方法,效率很低,而上面求导a a a
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import numpy as npclass SimpleLinearRegression2 : def __init__ (self ): self .a_ = None self .b_ = None def fit (self, x_train, y_train ): assert x_train.ndim==1 ,\ "Simple Linear Regression can only slove single feature training data" assert len (x_train) == len (y_train),\ "the size of x_trian must be equle to the size of y_train" x_mean, y_mean = np.mean(x_train), np.mean(y_train) numerator = (x_train-x_mean).dot(y_train-y_mean) denominator = (x_train-x_mean).dot(x_train-x_mean) self .a_ = numerator/denominator self .b_ = y_mean - self .a_*x_mean return self def predict (self, x_predict ): assert x_predict.ndim==1 ,\ "Simple Linear Regression can only slove single feature training data" assert self .a_ is not None and self .b_ is not None ,\ "must fit before predict" return np.array([self ._predict(x) for x in x_predict]) def _predcit (self, x_single ): return self .a_*x_single + self .b_ def __repr__ (self ): return "SimpleLinearRegression2()"
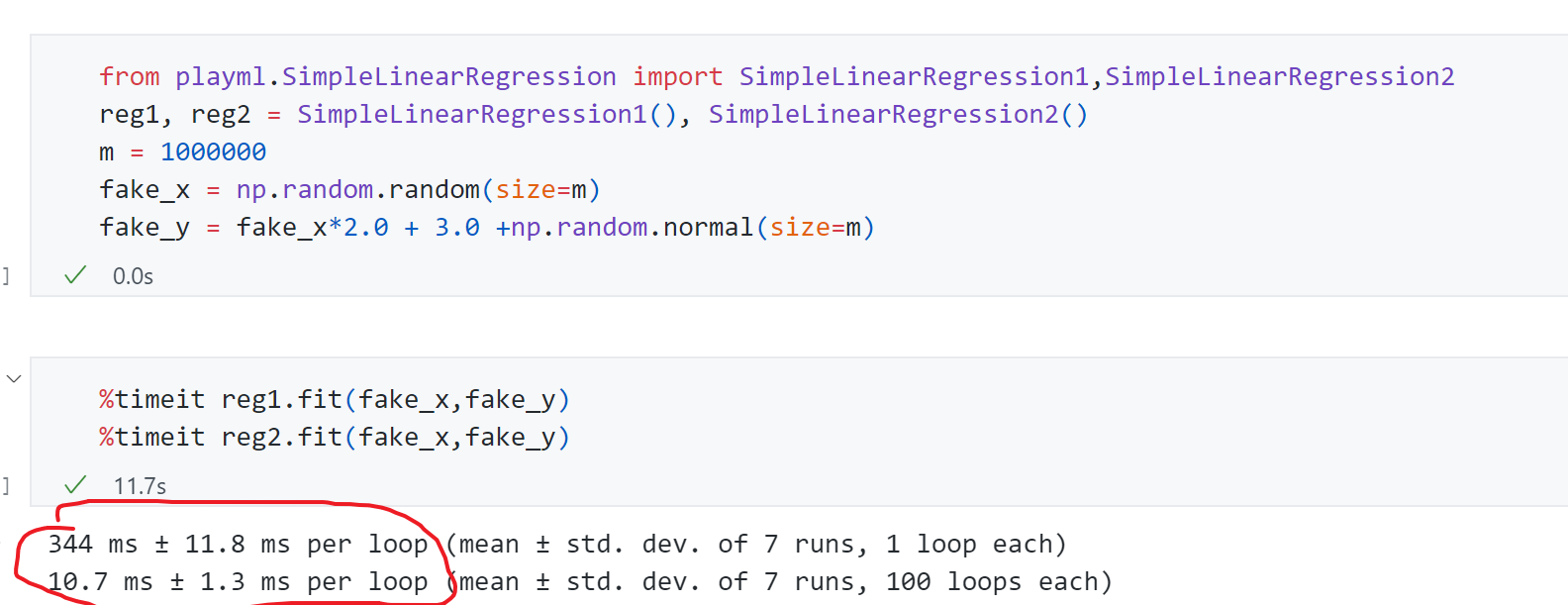
性能测试结果如下:
第一个for 循环版本平均用时344ms ,第二个向量化版本平均用时11ms , 性能提升了30倍 左右。
回归算法评价指标
前面训练目标主要是针对训练集而言:
目标 : 找到 a , b 使得 ∑ i = 1 m ( y t r a i n ( i ) − y ^ t r a i n ( i ) ) 2 尽可能小 目标:找到a,b使得\sum_{i=1}^{m}(y^{(i)}_{train}-\hat{y}_{train}^{(i)})^2尽可能小
目标 : 找到 a , b 使得 i = 1 ∑ m ( y t r ain ( i ) − y ^ t r ain ( i ) ) 2 尽可能小
然后基于训练得到的模型得到:
y ^ t e s t ( i ) = a x t e s t ( i ) + b 衡量标准 : ∑ i = 1 m ( y t e s t ( i ) − y ^ t e s t ( i ) ) 2 \hat{y}_{test}^{(i)}=ax^{(i)}_{test}+b\\
衡量标准:\sum_{i=1}^{m}(y^{(i)}_{test}-\hat{y}_{test}^{(i)})^2
y ^ t es t ( i ) = a x t es t ( i ) + b 衡量标准 : i = 1 ∑ m ( y t es t ( i ) − y ^ t es t ( i ) ) 2
但有个存在的问题就是这个衡量标准是跟m相关的,假如一个A算法得到误差是1000,另一个B算法是800,就能说明B算法好吗?显然不是,假如A算法是1000个样本误差和为1000,而B算法是10个样本误差和为800,显然A算法更好,因此对该指标很自然的一个改进就是:
1 m ∑ i = 1 m ( y t e s t ( i ) − y ^ t e s t ( i ) ) 2 均方误差 M S E ( M e a n S q u a r e d E r r o r ) \frac{1}{m}\sum_{i=1}^{m}(y^{(i)}_{test}-\hat{y}_{test}^{(i)})^2\\
均方误差MSE(Mean \quad Squared \quad Error)
m 1 i = 1 ∑ m ( y t es t ( i ) − y ^ t es t ( i ) ) 2 均方误差 MSE ( M e an Sq u a re d E rror )
但这个衡量标准还有一个小问题就是量纲上问题,比如如果y y y
1 m ∑ i = 1 m ( y t e s t ( i ) − y ^ t e s t ( i ) ) 2 均方根误差 R M S E ( R o o t M e a n S q u a r e d E r r o r ) \sqrt{\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}_{test}-\hat{y}_{test}^{(i)})^2}\\
均方根误差RMSE(Root\quad Mean \quad Squared \quad Error)
m 1 i = 1 ∑ m ( y t es t ( i ) − y ^ t es t ( i ) ) 2 均方根误差 RMSE ( R oo t M e an Sq u a re d E rror )
另外一个评测标准:
1 m ∑ i = 1 m ∣ y t e s t ( i ) − y ^ t e s t ( i ) ∣ 平均绝对误差 M A E ( M e a n A b s o l u t e E r r o r ) \frac{1}{m}\sum_{i=1}^{m}|y^{(i)}_{test}-\hat{y}_{test}^{(i)}|\\
平均绝对误差MAE( Mean \quad Absolute \quad Error)
m 1 i = 1 ∑ m ∣ y t es t ( i ) − y ^ t es t ( i ) ∣ 平均绝对误差 M A E ( M e an A b so l u t e E rror )
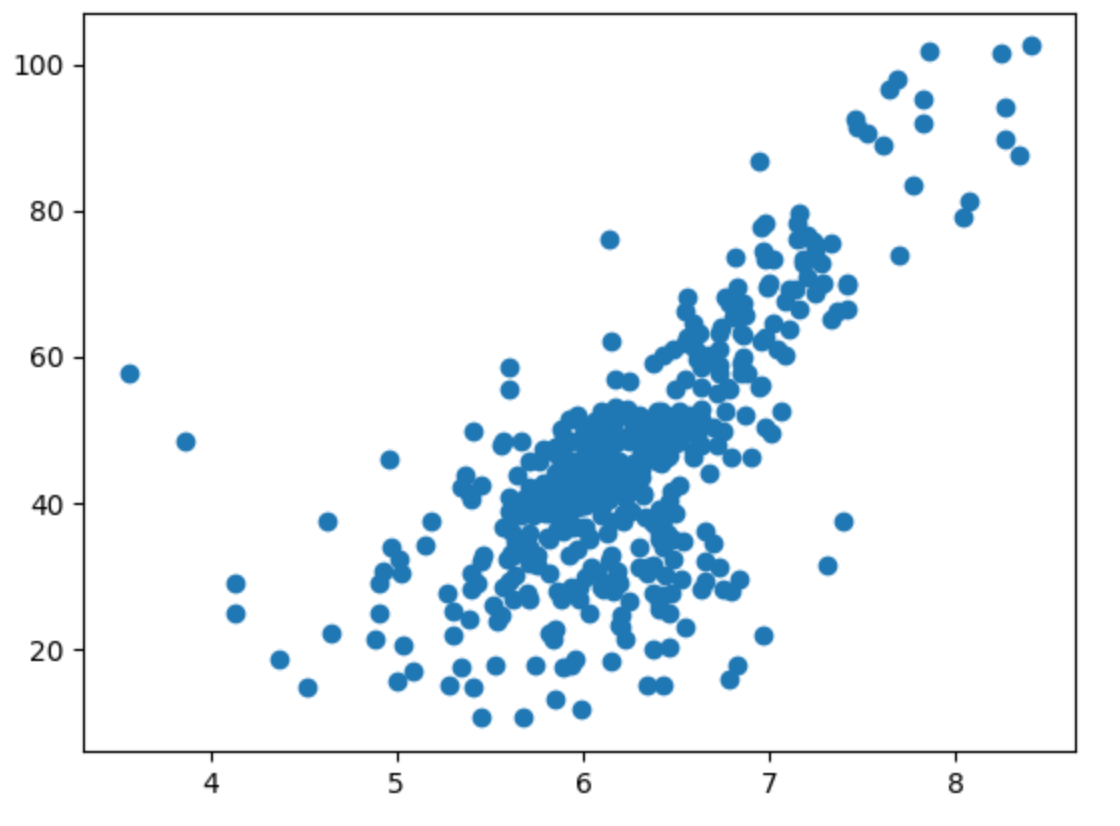
具体实现选用Boston房产数据:
其中x轴代表每个房产中平均的房间数量,y轴代表房产价格(万美元)
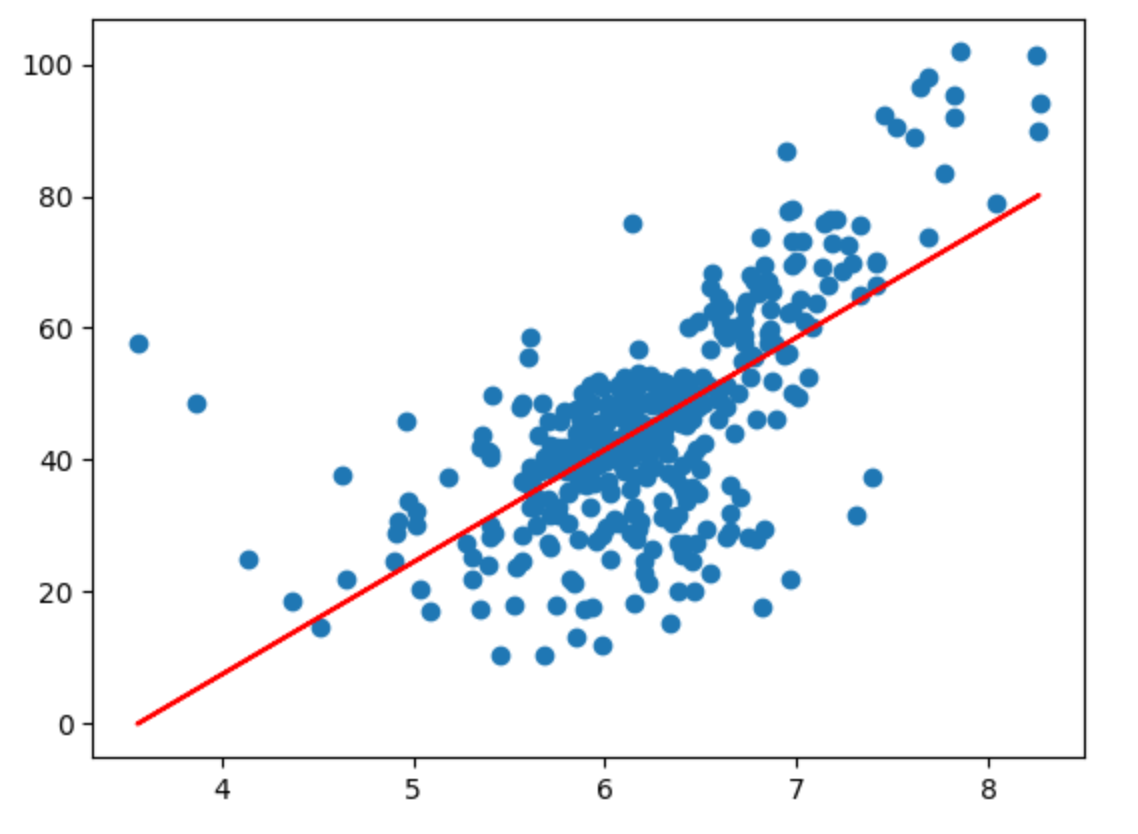
然后使用封装的代码拟合求解:
1 2 3 4 5 6 7 8 9 10 from playml.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(x, y, seed=666 ) from playml.SimpleLinearRegression import SimpleLinearRegression2reg = SimpleLinearRegression2() reg.fit(X_train, y_train) plt.scatter(X_train, y_train) plt.plot(X_train,reg.predict(X_train),"r" ) plt.show()
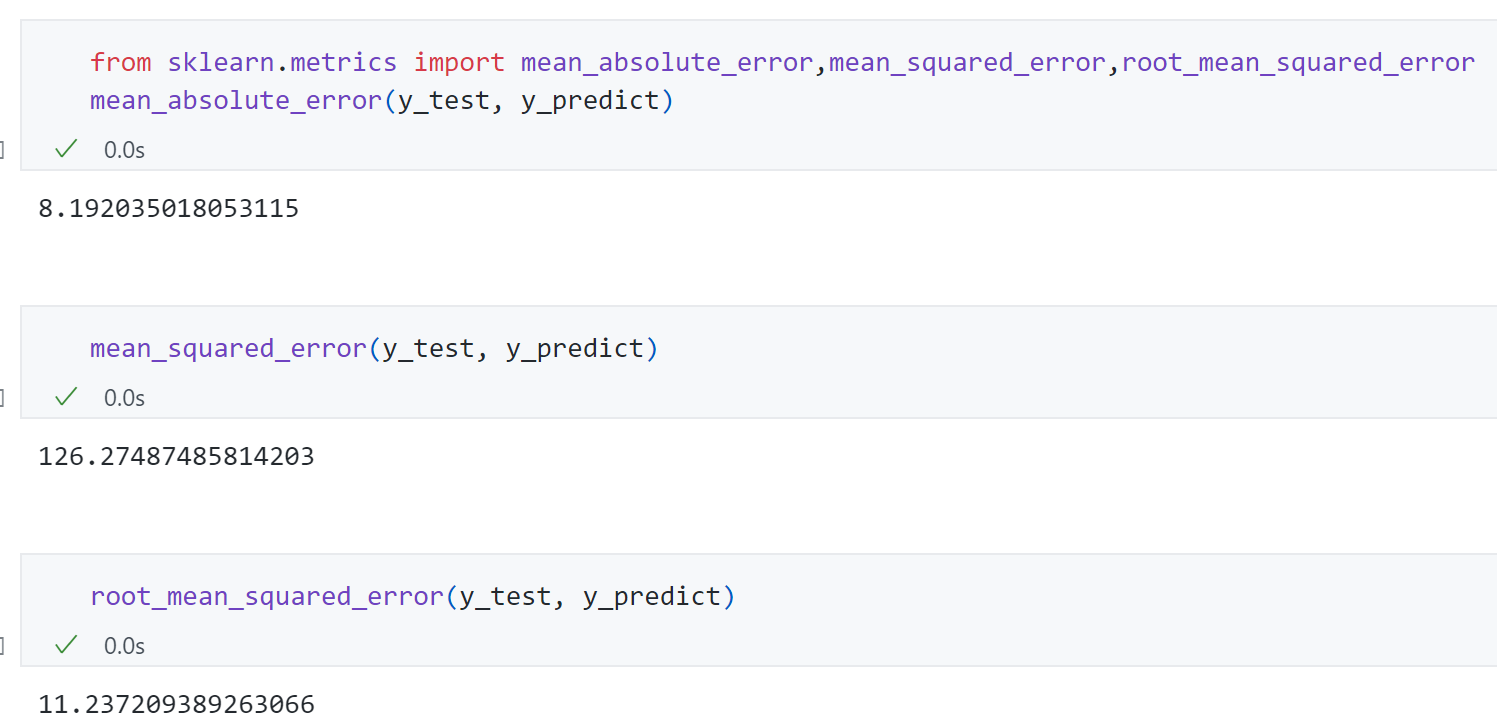
计算MSE,RMSE,MAE三个指标:
1 2 3 mse_test = np.sum ((y_predict-y_test)**2 )/len (y_test) rmse = np.sqrt(mse_test) mae_test = np.sum (np.abs (y_predict-y_test))/len (y_test)
求得MSE,RMSE,MAE的结果分别为126.27487485814203,11.237209389263066,8.192035018053115.
封装指标:
1 2 3 4 5 6 7 8 9 10 11 12 13 def mean_squared_error (y_true, y_predict ): assert len (y_true) == len (y_predict),\ "the size of y_true must be equal to the size of y_predict" return np.sum ((y_predict-y_true)**2 )/len (y_true) def root_mean_squared_error (y_true, y_predict ): return np.sqrt(mean_squared_error(y_true, y_predict)) def mean_absolute_error (y_true, y_predict ): assert len (y_true) == len (y_predict),\ "the size of y_true must be equal to the size of y_predict" return np.sum (np.abs (y_predict-y_true))/len (y_true)
用Scikit-learn中的函数求解:
发现数值结果同我们上面计算的一样.
RMSE VS MAE
从上面结果可以发现MAE 结果8.19比RMSE 的结果11.23略小 ,为什么呢?通过RMSE的算式就可以发现,RMSE是先平方在开方,如果错误值很大比如100经过平方就扩大到了10000,即RMSE有放大我们样本中预测结果和真实结果之间较大的那个差距的趋势 ,而MAE直接反映的样本的预测结果和真实结果之间的差距,没有平方操作。也正是如此,从某种程度来讲,我们尽量让RMSE这个值更加小相对来说意义更大,这背后意味着整个样本错误中那个最大的错误值相应的比较小 。